- Алгоритм кодирования речи CELP
-
Алгоритм кодирования речи CELP
Лине́йное предсказа́ние с мультико́довым управле́нием (англ. Code Excited Linear Prediction, CELP) представляет собой алгоритм кодирования речи, первоначально предложенный М. Р. Шредером и Б. С. Аталом в 1985 году. В то время алгоритм обеспечивал значительно лучшее качество, чем существовавшие тогда алгоритмы с низким битрейтом, такие, как аудиокодеки RELP и LPC (например, FS-1015). Наряду с вариантами, как, например, ACELP, RCELP, LD-CELP и VSELP, на сегодня это наиболее широко используемый алгоритм кодирования речи. CELP в настоящее время используется как общий термин для класса алгоритмов, а не для определенного кодека.
Содержание
Введение
Алгоритм CELP базируется на четырех основных идеях:
- Использование модели источника-фильтра для воспроизведения речи на основе линейного предсказания (ЛП);
- Использование адаптивной и фиксированной кодовых таблиц в качестве базы для модели линейного предсказания;
- Замкнутый поиск в «перцептуально взвешенном домене».
- Применение векторного квантования (VQ)
Оригинальный алгоритм Шредера и Атала в 1983 году, при запуске на суперкомпьютере Cray I, требовал 150 секунд для кодирования речевого сигнала длиной 1 секунду. С возникновением более эффективных способов реализации таблиц кодов и совершенствованием вычислительных возможностей- запуск алгоритма стал возможен во встраиваемых устройствах, таких как мобильные телефоны.
CELP декодер
Прежде, чем исследовать сложный процесс кодирования CELP мы рассмотрим принцип работы декодера. Иллюстрация (ниже дана внешняя ссылка на схему) описывает универсальный декодер CELP. Возбуждение производится через суммирование вкладов от адаптивной (иначе тактовой) таблицы кодов и фиксированной (иначе стохастической) таблицы кодов:
где ea[n] является адаптивным (тактовым) взносом таблицы кодов и ef[n] является фиксированным (стохастическим) вкладом таблицы кодов. Фиксированная таблица кодов- векторный словарь квантования, который является (неявно или явно) жестко закодированным в кодек. Эта таблица кодов может быть алгебраической ACELP или сохраненной явно (например. Speex). Записи в адаптивной таблице кодов состоят из отсроченных версий возбуждения. Это позволяет эффективно кодировать периодические сигналы, такие как человеческая речь.
У фильтра, который формирует возбуждение, есть все полюса модели в форме 1 / A (Z), где A (Z)-называется фильтром прогнозирования и получения, с применением линейного прогнозирования алгоритм Левинсона-Дарбина (Levinson-Durbin). Этот фильтр применим не только потому что использует все полюса, но и потому что его легко вычислить и это хорошее представление человеческого голоса.
Кодер CELP
Основной принцип, заключенный в основе CELP называют (Абсолютным) «Анализом через синтез», что означает, что кодирование (анализ) выполнено, перцепционно оптимизируя декодированный сигнал в замкнутом цикле. В теории, лучший поток CELP был бы произведен в результате комбинаций всех возможных наборов двоичных знаков и выбором тот, который производит декодированный сигнал наилучшего звучания. Это очевидно не возможно по двум причинам: сложность реализации выше любых в настоящее время доступных аппаратных средств, и критерий отбора «лучшее звучание» подразумевает в качестве слушателя- человека.
Чтобы осуществить кодирования в реальном времени, используя ограниченные вычислительные ресурсы, поиск CELP разбит на мелкие, более управляемые, последовательные поиски, используя простую перцептуальную функцию надбавки. Как правило, кодирование выполнено в следующем порядке:
- Линейные Коэффициенты Предсказания (ЛКП) вычислены и квантованы, обычно как LSP
- Происходит поиск по адаптивной (тактовой) таблице кодов, и ее содействие/взнос/ удаляется
- Поиск по фиксированной (стохастической) таблице кодов
Искажение шумом
Большинство (если не все) современные звуковые кодеки, пытаются сформировать искажение в кодировании так, чтобы оно проявилось главным образом в тех частотных областях, где его не может уловить человеческое ухо. Например, ухо более терпимо к искажению в частях звукового диапазона, которые громче и наоборот. Именно поэтому вместо минимизации квадратичной ошибки, CELP минимизирует ошибки на взвешенной области. Взвешивающий результат по кривой W (z), как правило, вытекает из фильтра ЛКП при помощи расширения полосы пропускания:
где γ1 > γ2.
Внешние ссылки
Wikimedia Foundation. 2010.
CELP — Линейное предсказание с мультикодовым управлением (англ. Code Excited Linear Prediction, CELP) представляет собой алгоритм кодирования речи, первоначально предложенный М. Р. Шредером и Б. С. Аталом в 1985 году. В то время … Википедия
Алгоритм фрактального сжатия — Треугольник Серпинского изображение, задаваемое тремя аффинными преобразованиями Фрактальное сжатие изображений алгоритм сжатия изображений c … Википедия
Алгоритм Шеннона — Алгоритм Шеннона Фано один из первых алгоритмов сжатия, который впервые сформулировали американские учёные Шеннон и Фано (англ. Robert Fano). Данный метод сжатия имеет большое сходство с алгоритмом Хаффмана, который появился на… … Википедия
Алгоритм Шеннона — Фано — Алгоритм Шеннона Фано один из первых алгоритмов сжатия, который впервые сформулировали американские учёные Шеннон и Фано (англ. Fano). Данный метод сжатия имеет большое сходство с алгоритмом Хаффмана, который появился на несколько лет … Википедия
Алгоритм Лемпеля — Зива — Велча — Алгоритм Лемпеля Зива Велча (Lempel Ziv Welch, LZW) это универсальный алгоритм сжатия данных без потерь, созданный Абрахамом Лемпелем (Abraham Lempel), Якобом Зивом (Jacob Ziv) и Терри Велчем (Terry Welch). Он был опубликован… … Википедия
Алгоритм Лемпеля — Алгоритм Лемпеля Зива Велча (Lempel Ziv Welch, LZW) это универсальный алгоритм сжатия данных без потерь, созданный Абрахамом Лемпелем (англ. Abraham Lempel), Якобом Зивом (англ. Jacob Ziv) и Терри Велчем… … Википедия
Алгоритм сжатия PPM — У этого термина существуют и другие значения, см. Ppm. PPM (англ. Prediction by Partial Matching предсказание по частичному совпадению) адаптивный статистический алгоритм сжатия данных без потерь, основанный на контекстном… … Википедия
Фрактальное сжатие — Треугольник Серпинского изображение, задаваемое тремя аффинными преобразованиями Фрактальное сжатие изображений это алгоритм сжатия изображений c потерями, основанный на применении систем итерируемых функций (IFS, как правило являющимися… … Википедия
Код Хаффмана — Алгоритм Хаффмана адаптивный жадный алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью. Был разработан в 1952 году аспирантом Массачусетского технологического института Дэвидом Хаффманом при написании им … Википедия
Код Хаффмена — Алгоритм Хаффмана (англ. Huffman) адаптивный жадный алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью. Был разработан в 1952 году доктором Массачусетского технологического института Дэвидом Хаффманом. В настоящее… … Википедия
Алгоритм кодирования речи CELP
![e[n]=e_a[n]+e_f[n]\,](http://dic.academic.ru/pictures/wiki/files/101/e98040affa69559d4ee568c2f7e480d6.png)
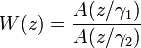
{kind=link}
18+
© Академик, 2000-2025
- Обратная связь: Техподдержка, Реклама на сайте
Экспорт словарей на сайты, сделанные на PHP, Joomla, Drupal, WordPress, MODx.