- ПОСЛЕДОВАТЕЛЬНЫЙ АНАЛИЗ
раздел математич. статистики, характерной чертой к-рого является то, что число производимых наблюдений (момент остановки наблюдений) не фиксируется заранее, а выбирается по ходу наблюдений в зависимости от значений поступающих данных. Стимулом к интенсивному развитию и применению в статистич. практике последовательных методов послужили работы А. Вальда (A. Wald). Им было установлено, что в задаче различения (по результатам независимых наблюдений) двух простых гипотез т. н. последовательный критерий отношений вероятностей дает значительный выигрыш в среднем числе производимых наблюдений по уравнению с наиболее мощным классич. способом различения (определяемой леммой Неймана - Пирсона) с фиксированным объемом выборки и теми же вероятностями ошибочных решений.
Основные принципы П. а. состоят в следующем. Пусть x1, x2, . . . - последовательность независимых одинаково распределенных случайных величин и функция распределения
 зависит от неизвестного параметра q, принадлежащего нек-рому параметрич. множеству Q. Задача состоит в том, чтобы по результатам наблюдений вынести то или иное решение об истинном значении неизвестного параметра q.
зависит от неизвестного параметра q, принадлежащего нек-рому параметрич. множеству Q. Задача состоит в том, чтобы по результатам наблюдений вынести то или иное решение об истинном значении неизвестного параметра q.
В основе любой статистич. задачи решения лежат пространство Dзаключительных (терминальных) решений d(о значениях параметра q) и правило t, определяющее момент прекращения наблюдений, в к-рый и выносится заключительное решение. В классич. методах наблюдений момент t является неслучайным и фиксированным заранее; в последовательных методах t является случайной величиной, не зависящей от "будущего" (марковский момент, момент остановки). Формально, пусть
 есть s-алгебра, порожденная случайными величинами x1 ,. . .,x п. Случайная величина t=t(w), принимающая значения 0, 1, . . ., +
есть s-алгебра, порожденная случайными величинами x1 ,. . .,x п. Случайная величина t=t(w), принимающая значения 0, 1, . . ., + , наз. марковским моментом, если событие.
, наз. марковским моментом, если событие.  для каждого
для каждого  (
(
 ). Пусть
). Пусть  -совокупность тех измеримых множеств А, для к-рых
-совокупность тех измеримых множеств А, для к-рых  и для каждого
и для каждого  . Если
. Если 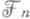 интерпретируется как совокупность событий, наблюдаемых до случайного момента n (включительно), то
интерпретируется как совокупность событий, наблюдаемых до случайного момента n (включительно), то 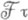 можно интерпретировать как совокупность событий, наблюдаемых до случайного момента t (включительно). Заключительное (терминальное) решение d=d(w) есть
можно интерпретировать как совокупность событий, наблюдаемых до случайного момента t (включительно). Заключительное (терминальное) решение d=d(w) есть  - измеримая функция со значениями в пространстве D. Пара d= (t, d)таких функций наз. (последовательным) решающим правилом.
- измеримая функция со значениями в пространстве D. Пара d= (t, d)таких функций наз. (последовательным) решающим правилом.
Для выделения среди решающих правил "оптимального" задают функцию риска
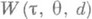 и рассматривают математич. ожидание
и рассматривают математич. ожидание  . Существуют разные подходы к определению понятия оптимального решающего правила d* = (t*, d*). Один из них, бейесовский, основан на предположении, что параметр q является случайной величиной с априорным распределением p=p(dq). Тогда имеет смысл говорить о p-риске
. Существуют разные подходы к определению понятия оптимального решающего правила d* = (t*, d*). Один из них, бейесовский, основан на предположении, что параметр q является случайной величиной с априорным распределением p=p(dq). Тогда имеет смысл говорить о p-риске

и называть правило d*=(t*, d* )оптимальным байесовским решением (или p-оптимальным), если
 для любого другого (допустимого) правила. Наиболее распространенной формой риска W(t,q, d )является риск вида сt+W1(q, d), где константа
для любого другого (допустимого) правила. Наиболее распространенной формой риска W(t,q, d )является риск вида сt+W1(q, d), где константа  интерпретируется как стоимость единичного наблюдения, a W1(q, d).является функцией потерь от заключительного решения.
интерпретируется как стоимость единичного наблюдения, a W1(q, d).является функцией потерь от заключительного решения.
В бейесовских задачах отыскание оптимального заключительного решения d*, как правило, не вызывает трудностей, и основные усилия направлены на отыскание оптимального момента остановки t*. При этом большинство задач П. а. укладывается в следующую схему "оптимальных правил остановки".
Пусть
 , - цепь Маркова в фазовом пространстве
, - цепь Маркова в фазовом пространстве  , где х п - состояние цени в момент времени п,s-алгёбра
, где х п - состояние цени в момент времени п,s-алгёбра  интерпретируется как совокупность событий, наблюдаемых до момента времени п(включительно), а R х - распределение вероятностей, отвечающее начальному состоянию
интерпретируется как совокупность событий, наблюдаемых до момента времени п(включительно), а R х - распределение вероятностей, отвечающее начальному состоянию  . Предполагается, что, прекращая наблюдение в момент времени п, получают выигрыш g(xn). Тогда средний выигрыш от остановки в момент т есть Exg(xt), где х - начальное состояние. Функцию s(x).sup Exg(xt), где sup берется по всем (конечным) моментам остановки t, наз. ценой, а момент t для к-рого
. Предполагается, что, прекращая наблюдение в момент времени п, получают выигрыш g(xn). Тогда средний выигрыш от остановки в момент т есть Exg(xt), где х - начальное состояние. Функцию s(x).sup Exg(xt), где sup берется по всем (конечным) моментам остановки t, наз. ценой, а момент t для к-рого  для всех
для всех  , наз. e- оптимальным моментом остановки. О-оптимальные моменты наз. оптимальными. Основные вопросы теории "оптимальных правил остановки" таковы: какова структура цены s(x), как ее найти, когда существуют e-оптимальные и оптимальные моменты, какова их структура. Ниже приведен один из типичных результатов, касающихся поставленных вопросов.
, наз. e- оптимальным моментом остановки. О-оптимальные моменты наз. оптимальными. Основные вопросы теории "оптимальных правил остановки" таковы: какова структура цены s(x), как ее найти, когда существуют e-оптимальные и оптимальные моменты, какова их структура. Ниже приведен один из типичных результатов, касающихся поставленных вопросов.
Пусть функция g(x)ограничена:
 Тогда цена s(x)является наименьшей эксцессивной мажорантой функции g(x), т. е. наименьшей из функций f(x), удовлетворяющих двум свойствам
Тогда цена s(x)является наименьшей эксцессивной мажорантой функции g(x), т. е. наименьшей из функций f(x), удовлетворяющих двум свойствам
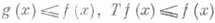
где
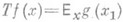 . При этом момент
. При этом момент

является e-оптимальньш для всякого e>0, цена s(x).удовлетворяет уравнению Вальда - Беллмана

и может быть найдена по формуле
 ,
,
где
 .
.
В том случае, когда множество Еконечно, момент

будет оптимальным. В общем случае момент t0 является оптимальным, если
 . Пусть
. Пусть

В соответствии с определением

Иначе говоря, прекращение наблюдений следует производить при первом попадании в множество Г. В связи с этим множество Сназ. множеством продолжения наблюдений, а Г - множеством прекращения наблюдений.
Иллюстрацией этих результатов может служить задача различения двух простых гипотез, на к-рой А. Вальд продемонстрировал преимущество последовательных методов по сравнению с классическими. Пусть параметр 0 принимает два значения 1 и 0 с априорными вероятностями p и 1-p соответственно и множество заключительных решений Dсостоит также из двух точек: d=1 (принимается гипотеза H1,:q=1) и d=0 (принимается гипотеза H0:q=0). Если функцию W1(q, d).выбрать в виде
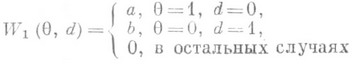
и положить

то для Rd (p) получают выражение
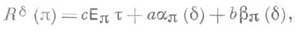
где

- вероятности ошибок первого и второго рода, а Р p означает распределение вероятностей в пространстве наблюдений, отвечающее априорному распределению p. Если
 - апостериорная вероятность гипотезы H1:q=1 относительно s-алгебры
- апостериорная вероятность гипотезы H1:q=1 относительно s-алгебры  , то
, то

где

Из общей теории оптимальных правил остановки, примененной к х п=( п,pn), следует, что функция r(p) =inftRd(p) удовлетворяет уравнению

Отсюда, в силу выпуклости вверх функций r(p), g(p), Tr(p), можно вывести, что найдутся два числа 0
 А<B
А<B 1 такие, что область продолжения С={p:А<p<B}, а область прекращения наблюдений Г= = [0, 1](A,В). При этом момент остановки
1 такие, что область продолжения С={p:А<p<B}, а область прекращения наблюдений Г= = [0, 1](A,В). При этом момент остановки

является оптимальным (p0=p).
Если р 0 (х).и р 1 (х) - плотности распределений F0 (х)
и F1 (х).(по мере
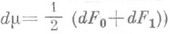 , a
, a
 - отношение правдоподобия, то область продолжения наблюдений (см. рис. 1) может быть записана в виде
- отношение правдоподобия, то область продолжения наблюдений (см. рис. 1) может быть записана в виде

и
 .
.
При этом если
 , то выносится решение d=l, т. е. принимаетея гипотеза H1 : q=1. Если же
, то выносится решение d=l, т. е. принимаетея гипотеза H1 : q=1. Если же  , то - гипотеза H0 : q=0.
, то - гипотеза H0 : q=0.
Структура этого оптимального решающего правила сохраняется и для задачи различения гипотез в условноэкстремальной постановке, состоящей в следующем.

Для каждого решающего правила d=(t, d).вводят вероятности ошибок a(d)=P1(d=0), b(d)=P0(d=l) и задают два числа a>0 и b>0; и пусть, далее, D (a, b) - совокупность всех решающих правил с
 и
и  . Следующий фундаментальный результат был получен А. Вальдом. Если a+b<1 и среди критериев d=(t, d), основанных на отношении правдоподобия jn и имеющих вид
. Следующий фундаментальный результат был получен А. Вальдом. Если a+b<1 и среди критериев d=(t, d), основанных на отношении правдоподобия jn и имеющих вид
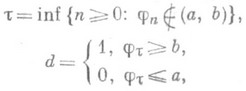
найдутся такие а=а* и b=b*, что вероятности ошибок первого и второго рода в точности равны a и b, то решающее правило d* = (t*, d*).с а= а* и b= b* является в классе D (a, b) оптимальным в том смысле, что

для любого
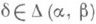
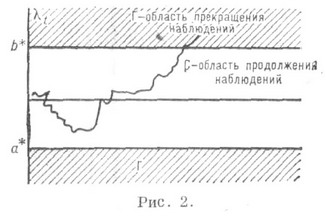
Преимущества последовательного решающего правила d*=(t*, d* )по сравнению с классическим проще проиллюстрировать на примере задачи различения двух гипотез Н 0:q=0 и H1:0=1 относительно локального среднего значения q винеровского процесса xt c единичной диффузией. Оптимальное последовательное решающее правило d*=(t*, d*), обеспечивающее заданные вероятности ошибок a и b первого и второго рода соответственно, описывается следующим образом:

где lt=1n jt и отношение правдоподобия (производная меры, отвечающей q=1, по мере, отвечающей q=0) jt
 (см. рис. 2).
(см. рис. 2).
Оптимальное классич. правило
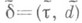 (согласно лемме Неймана - Пирсона) описывается следующим
(согласно лемме Неймана - Пирсона) описывается следующим
образом:

где

а cg - корень уравнения

Поскольку
 , где
, где

то

Численный подсчет показывает, что при


Иначе говоря, при рассматриваемых значениях ошибок первого и второго рода оптимальный последовательный метод различения требует примерно в два раза меньше наблюдений, чем оптимальный метод с фиксированным числом наблюдений. Более того, если a=b, то

Лит.:[1] Вальд А., Последовательный анализ, пер. с англ., М., 1960; [2] Ширяев А. Н., Статистический последовательный анализ, М., 1976. А. Н. Ширяев.
Математическая энциклопедия. — М.: Советская энциклопедия. И. М. Виноградов. 1977—1985.