- Tfidf
-
TF-IDF (от англ. TF — term frequency, IDF — inverse document frequency) — статистическая мера, используемая для оценки важности слова в контексте документа, являющегося частью коллекции документов или корпуса. Вес некоторого слова пропорционален количеству употребления этого слова в документе, и обратно пропорционален частоте употребления слова в других документах коллекции.
Мера TF-IDF часто используется в задачах анализа текстов и информационного поиска, например, как один из критериев релевантности документа поисковому запросу, при расчёте меры близости документов при кластеризации.
Содержание
Структура формулы
TF (term frequency — частота слова) — отношение числа вхождения некоторого слова к общему количеству слов документа. Таким образом, оценивается важность слова ti в пределах отдельного документа.
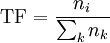 ,
,где ni есть число рассматриваемых употреблений слова, а в знаменателе — общее число словоупотреблений.
IDF (inverse document frequency — обратная частота документа) — инверсия частоты, с которой некоторое слово встречается в документах коллекции. Учёт IDF уменьшает вес широкоупотребительных слов.
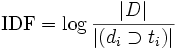 ,[1]
,[1]где
- |D| — количество документов в корпусе;
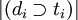 — количество документов, в которых встречается ti (когда
— количество документов, в которых встречается ti (когда 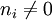 ).
).
Таким образом, мера TF-IDF является произведением двух сомножителей: TF и IDF.
Большой вес в TF-IDF получат слова с высокой частотой в пределах конкретного документа и с низкой частотой употреблений в других документах.
Числовое применение
Существуют различные формулы, основанные на методе TF-IDF. Они отличаются коэффициентами, нормировками, использованием логарифмированных шкал. В частности, поисковая система Яндекс долгое время использовала нормировку по самому частотному термину в документе[1].
Одной из наиболее популярных формул является формула BM25[2].
Пример
Если документ содержит 100 слов и слово[2] «заяц» встречается в нём 3 раза, то частота слова (TF) для слова «заяц» в документе будет 0,03 (3/100). Одним из вариантов вычисления частоты документа (IDF) определяется как количество документов содержащих слово «заяц», разделенное на количество всех документов. Таким образом, если «заяц» содержится в 1000 документов из 10 000 000 документов, то частота документа (DF) будет равной 0,0001 (1000/10000000). Для расчета окончательного значения веса слова необходимо разделить TF на DF (или умножить на IDF). В данном примере, TF-IDF вес для слова «заяц» в коллекции документов будет 300 (0,03/0,0001).
Применение в модели векторного пространства
Мера TF-IDF часто используется для представлении документов коллекции в виде числовых векторов, отражающих важность использования каждого слова из некоторого набора слов (количество слов набора определяет размерность вектора) в каждом документе. Подобная модель называется векторной моделью (VSM) и даёт возможность сравнивать тексты, сравнивая представляющие их вектора в какой либо метрике (евклидово расстояние, косинусная мера, манхэттенское расстояние, расстояние Чебышева и др.), т. е. производя кластерный анализ.
Примечания
- ↑ В некоторых вариантах формулы не используется логарифмирование.
- ↑ Обычно перед анализом документа слова приводятся морфологическим анализатором к нормальной форме.
Литература
- Дж Солтон. Динамические библиотечно-поисковые системы. М.: - Мир, 1979.
- Salton, G. and McGill, M. J. 1983 Introduction to modern information retrieval. McGraw-Hill, ISBN 0-07-054484-0.
- Salton, G., Fox, E. A. and Wu, H. 1983 Extended Boolean information retrieval. Commun. ACM 26, 1022—1036.
- Salton, G. and Buckley, C. 1988 Term-weighting approaches in automatic text retrieval. Information Processing & Management 24(5): 513—523
- Федоровский А.Н, Костин М. Ю. Mail.ru на РОМИП-2005 // в сб. «Труды РОМИП’2005» Труды третьего российского семинара по оценке методов информационного поиска. Под ред. И. С. Некрестьянова, стр. 106—124, Санкт-Петербург: НИИ Химии СПбГУ, 2005.
- М. В. Губин. Модели и методы представления текстового документа в системах информационного поиска
См. также
- Закон Ципфа
- Частотность
Ссылки
Wikimedia Foundation. 2010.