- Вычислительный конвейер
-
Конве́йер — способ организации вычислений, используемый в современных процессорах и контроллерах с целью повышения их производительности (увеличения числа инструкций, выполняемых в единицу времени), технология, используемая при разработке компьютеров и других цифровых электронных устройств.
Идея заключается в разделении обработки компьютерной инструкции на последовательность независимых стадий с сохранением результатов в конце каждой стадии. Это позволяет управляющим цепям процессора получать инструкции со скоростью самой медленной стадии обработки, однако при этом намного быстрее, чем при выполнении эксклюзивной полной обработки каждой инструкции от начала до конца.
 Простой пятиуровневый конвейер в RISC-процессорах
Простой пятиуровневый конвейер в RISC-процессорах
На иллюстрации справа показан простой пятиуровневый конвейер в RISC-процессорах. Здесь:
- IF (англ. Instruction Fetch) — получение инструкции,
- ID (англ. Instruction Decode) — раскодирование инструкции,
- EX (англ. Execute) — выполнение,
- MEM (англ. Memory access) — доступ к памяти,
- WB (англ. Register write back) — запись в регистр.
Вертикальная ось — последовательные независимые инструкции, горизонтальная — время. Зелёная колонка описывает состояние процессора в один момент времени, в ней самая ранняя, верхняя инструкция уже находится в состоянии записи в регистр, а самая последняя, нижняя инструкция только в процессе чтения.
Содержание
История
Сам термин «конвейер» пришёл из промышленности, где используется подобный принцип работы — материал автоматически подтягивается по ленте конвейера к рабочему, который осуществляет с ним необходимые действия, следующий за ним рабочий выполняет свои функции над получившейся заготовкой, следующий делает ещё что-то. Таким образом, к концу конвейера цепочка рабочих полностью выполняет все поставленные задачи, сохраняя высокий темп производства. Например, если на самую медленную операцию затрачивается одна минута, то каждая деталь будет сходить с конвейера через одну минуту.
Считается, что впервые конвейерные вычисления были использованы либо в проекте ILLIAC II (англ.), либо в проекте IBM Stretch (англ.). Проект IBM Stretch предложил термины «получение» (англ. Fetch), «расшифровка» (англ. Decode) и «выполнение» (англ. Execute), которые затем стали общеупотребительными.
Тактовый генератор
Многие современные процессоры управляются тактовым генератором. Процессор внутри состоит из логических элементов и ячеек памяти — триггеров. Когда приходит сигнал от тактового генератора, триггеры приобретают своё новое значение и «логике» требуется некоторое время для декодирования новых значений. Затем приходит следующий сигнал от тактового генератора, триггеры принимают новые значения, и так далее. Разбивая последовательности логических элементов на более короткие и помещая триггеры между этими короткими последовательностями, уменьшают время, необходимое логике для обработки сигналов. В этом случае длительность одного такта процессора может быть соответственно уменьшена.
Например, простейший конвейер RISC-процессоров можно представить пятью стадиями с наборами триггеров между стадиями:
- получение инструкции (англ. Instruction Fetch);
- декодирование инструкции (англ. Instruction Decode) и чтение регистров (англ. Register fetch);
- выполнение (англ. Execute);
- доступ к памяти (англ. Memory access);
- запись в регистр (англ. Register write back);
Конфликт конвейера
При написании ассемблерного кода (либо разработке компилятора, генерирующего последовательность инструкций) делается предположение, что результат выполнения инструкций будет точно таким, как если бы каждая инструкция заканчивала выполняться до начала выполнения следующей за ней. Использование конвейера сохраняет справедливость этого предположения, однако не обязательно сохраняет порядок выполнения инструкций. Ситуация, когда одновременное выполнение нескольких инструкций может привести к логически некорректной работе конвейера, известна как «конфликт конвейера (англ. Pipeline hazard)». Существуют различные методы устранения конфликтов (форвардинг (англ. Register forwarding) и другие).
Бесконвейерная архитектура
Бесконвейерная архитектура значительно менее эффективна из-за меньшей загрузки функциональных модулей процессора в то время, пока один или небольшое число модулей выполняет свою роль во время обработки инструкций. Конвейер не убирает полностью время простоя модулей в процессорах как таковое и не уменьшает время выполнения каждой конкретной инструкции, но заставляет модули процессора работать параллельно над разными инструкциями, увеличивая тем самым количество инструкций, выполняемых за единицу времени, а значит и общую производительность программ.
Процессоры с конвейером внутри устроены так, что обработка инструкций разделена на последовательность стадий, предполагая одновременную обработку нескольких инструкций на разных стадиях. Результаты работы каждой из стадий передаются через ячейки памяти на следующую стадию, и так — до тех пор, пока инструкция не будет выполнена. Подобная организация процессора, при некотором увеличении среднего времени выполнения каждой инструкции, тем не менее обеспечивает значительный рост производительности за счёт высокой частоты завершения выполнения инструкций.
Не все инструкции являются независимыми. В простейшем конвейере, где обработка инструкции представлена пятью стадиями, для обеспечения полной загрузки, в то время пока заканчивается обработка первой инструкции, должно обрабатываться параллельно ещё четыре последовательных независимых инструкции. Если последовательность содержит инструкции, зависимые от выполняемых в данный момент, то управляющая логика простейшего конвейера приостанавливает несколько начальных стадий конвейера, помещая этим самым в конвейер пустую инструкцию («пузырёк»), иногда неоднократно, — до тех пор, пока зависимость не будет разрешена. Существует ряд приёмов, таких как форвардинг, значительно снижающих необходимость приостанавливать в таких случаях часть конвейера. Однако зависимость между инструкциями, одновременно обрабатываемыми процессором, не позволяет добиться увеличения производительности кратно количеству стадий конвейера в сравнении с бесконвейерным процессором.
Преимущества и недостатки
Конвейер помогает не во всех случаях. Существует несколько возможных минусов. Конвейер инструкций можно назвать «полностью конвейерным», если он может принимать новую инструкцию каждый машинный цикл. Иначе в конвейер должны быть вынужденно вставлены задержки, которые выравнивают конвейер, при этом ухудшат его производительность.
Преимущества:
- Время цикла процессора уменьшается, таким образом увеличивая скорость обработки инструкций в большинстве случаев.
- Некоторые комбинационные логические элементы, такие как сумматоры или умножители могут быть ускорены путем увеличения количества логических элементов. Использование конвейера может предотвратить ненужное наращивание количества элементов.
Недостатки:
- Беcконвейерный процессор исполняет только одну инструкцию за раз. Это предотвращает задержки веток инструкций (фактически, каждая ветка задерживается), и проблемы, связанные с последовательными инструкциями, которые исполняются параллельно. Следовательно, схема такого процессора проще и он дешевле для изготовления.
- Задержка инструкций в беcконвейерном процессоре слегка ниже, чем в конвейерном эквиваленте. Это происходит из-за того, что в конвейерный процессор должны быть добавлены дополнительные триггеры.
- У беcконвейерного процессора скорость обработки инструкций стабильна. Производительность конвейерного процессора предсказать намного сложнее, и она может значительно различаться в разных программах.
Примеры
Общий конвейер
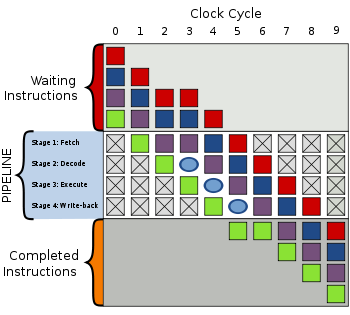
 Общий четырёхуровневых конвейер; цветные квадраты символизируют независимые друг от друга инструкции
Общий четырёхуровневых конвейер; цветные квадраты символизируют независимые друг от друга инструкцииСправа изображён общий конвейер с четырьмя стадиями работы:
- Получение (англ. Fetch)
- Раскодирование (англ. Decode)
- Выполнение (англ. Execute)
- Запись результата (англ. Write-back)
Верхняя серая область — список инструкций, которые предстоит выполнить. Нижняя серая область — список инструкций, которые уже были выполнены. И средняя белая область является самим конвейером.
Выполнение происходит следующим образом:
Цикл Действия 0 Четыре инструкции ожидают исполнения 1 - Зелёная инструкция забирается из памяти
2 - Зелёная инструкция раскодируется
- Фиолетовая инструкция забирается из памяти
3 - Зелёная инструкция выполняется (то есть исполняется то действие, которое она кодировала)
- Фиолетовая инструкция раскодируется
- Синяя инструкция забирается из памяти
4 - Итоги исполнения зелёной инструкции записываются в регистры или в память
- Фиолетовая инструкция выполняется
- Синяя инструкция раскодируется
- Красная инструкция забирается из памяти
5 - Зелёная инструкция завершилась
- Итоги исполнения фиолетовой инструкции записываются в регистры или в память
- Синяя инструкция выполняется
- Красная инструкция раскодируется
6 - Фиолетовая инструкция завершилась
- Результаты исполнения синей инструкция записываются в регистры или в память
- Красная инструкция выполняется
7 - Синяя инструкция завершилась
- Итоги исполнения красной инструкции записываются в регистры или в память
8 - Красная инструкция завершилась
9 Все инструкции были выполнены Пузырёк
 Пузырек в третьем такте обработки задерживает исполнение
Пузырек в третьем такте обработки задерживает исполнениеКогда в выполнении по каким-либо причинам случается небольшой сбой или задержка, в конвейере получается «пузырёк», в котором не происходит ничего полезного. Во втором такте обработка фиолетовой инструкции задерживается и вместо стадии расшифровки в третьем такте теперь находится пузырёк. Всё, что находится «за» фиолетовой инструкцией, испытывает задержку в один такт, тогда как всё, что находится «перед» фиолетовой инструкцией продолжает исполняться.
Очевидно, что наличие пузырька в конвейере даёт суммарное время исполнения в 8 тактов вместо 7 на схеме исполнения, показанной выше.
Пузырьки — это как заглушки, в которых не происходит ничего полезного при их прочтении, раскодировании, исполнении и записи результата. Они могут быть выражены при помощи инструкции NOP[1][2][3] ассемблера.
Пример 1
Допустим, типичная инструкция для сложения двух чисел это
СЛОЖИТЬ A, B, C. Эта инструкция суммирует значения, находящиеся в ячейках памяти A и B, а затем кладет результат в ячейку памяти C. В конвейерном процессоре контроллер может разбить эту операцию на последовательные задачи видаЗАГРУЗИТЬ A, R1 ЗАГРУЗИТЬ B, R2 СЛОЖИТЬ R1, R2, R3 ЗАПИСАТЬ R3, C загрузить следующую инструкцию
Ячейки R1, R2 и R3 являются регистрами процессора. Значения, которые хранятся в ячейках памяти, которые мы называем A и B, загружаются (то есть копируются) в эти регистры, затем суммируются, и результат записывается в ячейку памяти C.
В данном примере конвейер состоит из трех уровней — загрузки, исполнения и записи. Эти шаги называются, очевидно, уровнями или шагами конвейера.
В бесконвейерном процессоре, только один шаг может работать в один момент времени, поэтому инструкция должна полностью закончиться прежде, чем следующая инструкция в принципе начнется. В конвейерном процессоре, все эти шаги могут выполняться одновременно на разных инструкциях. Поэтому когда первая инструкция находится на шаге исполнения, вторая инструкция будет на стадии раскодирования, а третья инструкция будет на стадии прочтения.
Конвейер не уменьшает время, которое необходимо для того, чтобы выполнить инструкцию, но зато он увеличивает объём (число) инструкций, которые могут быть выполнены одновременно и таким образом уменьшает задержку между выполненными инструкциями — увеличивая т. н. пропускную способность. Чем больше уровней имеет конвейер, тем больше инструкций могут выполняться одновременно и тем меньше задержка между завершенными инструкциями. Каждый микропроцессор, произведенный в наши дни, использует как минимум двухуровневый конвейер.
Пример 2
Теоретический трёхуровневый конвейер:
Шаг Англ. название Описание Выборка Fetch Прочитать инструкцию из памяти Исполнение Execute Исполнить инструкцию Запись Write-back Записать результат в память и/или регистры Псевдоассемблерный листинг, который нужно выполнить:
ЗАГРУЗИТЬ 40, A ; загрузить число 40 в A КОПИРОВАТЬ A, B ; скопировать A в B СЛОЖИТЬ 20, B ; добавить 20 к B ЗАПИСАТЬ B, 0x0300 ; записать B в ячейку памяти 0x0300
Как это будет исполняться:
Такт Выборка Исполнение Запись Пояснение Такт 1 ЗАГРУЗИТЬ Инструкция ЗАГРУЗИТЬ читается из памяти. Такт 2 КОПИРОВАТЬ ЗАГРУЗИТЬ Инструкция ЗАГРУЗИТЬ выполняется, инструкция КОПИРОВАТЬ читается из памяти. Такт 3 СЛОЖИТЬ КОПИРОВАТЬ ЗАГРУЗИТЬ Инструкция ЗАГРУЗИТЬ находится на шаге записи результата, где её результат (то есть число 40) записывается в регистр А. В это же время, инструкция КОПИРОВАТЬ исполняется. Так как она должна скопировать содержимое регистра A в регистр B, она должна дождаться окончания инструкции ЗАГРУЗИТЬ. Такт 4 ЗАПИСАТЬ СЛОЖИТЬ СКОПИРОВАТЬ Загружена инструкция ЗАПИСАТЬ, тогда как инструкция СКОПИРОВАТЬ прощается с нами, а по инструкции СЛОЖИТЬ в данный момент производятся вычисления. И так далее. Следует учитывать, что иногда инструкции будут зависеть от итогов других инструкций (например, как наша инструкция СКОПИРОВАТЬ). Когда более, чем одна инструкция ссылается на определённое место, читая его (то есть используя в качестве входного операнда) либо записывая в него (то есть используя его в качестве выходного операнда), исполнение инструкций не в порядке, который был изначально запланирован в оригинальной программе может повлечь за собой «конфликт конвейера (англ. Hazard)» (о чём упоминалось выше). Существует несколько зарекомендовавших себя приёмов либо для предотвращения конфликтов, либо для их исправления, если они случились.
Трудности
Множество схем включают в себя конвейеры в 7, 10 или даже 20 уровней (как, например, в Pentium 4). Поздние ядра Pentium 4 с кодовыми именами Prescott и Cedar Mill (и их Pentium D-производные) имеют 31-уровневый конвейер, самый длинный среди популярных процессоров (Xelerator X10q имеет конвейер длиной более, чем в тысячу шагов.[4]). Обратной стороной медали в данном случае является необходимость сбрасывать весь конвейер в случае, если ход программы изменился (например, по условному оператору). Эту проблему пытаются решать предсказатели переходов. Предсказание переходов само по себе может только усугубить ситуацию, если предсказание производится плохо. В некоторых областях применения, таких как вычисления на суперкомпьютерах, программы специально пишутся так, чтобы как можно реже использовать условные операторы, поэтому очень длинные конвейеры весьма позитивно скажутся на общей скорости вычислений, так как длинные конвейеры проектируются так, чтобы уменьшить CPI (англ. Clocks Per Instruction, количество тактов на инструкцию). Если ветвление происходит постоянно, переорганизация таким образом, чтобы те инструкции, которые, скорее всего, понадобятся, были размещены в конвейере, может значительно уменьшить потери скорости по сравнению с необходимостью каждый раз полностью сбрасывать конвейер. Программы типа gcov могут использоваться для того, чтобы определять, как часто отдельные ветки исполняются на самом деле, используя технологию, известную как анализ покрытия кода (англ. Code coverage analysis), хотя на практике подобный анализ является последней мерой при оптимизации.
Высокая пропускная способность конвейеров оборачивается тормозами в случае, если в исполняемом коде содержится много условных переходов: процессор не знает, откуда читать следующую инструкцию, и поэтому вынужден ждать, когда закончится инструкция условного перехода, оставляя за ней пустой конвейер. После того, как ветка будет пройдена и станет известно, куда процессору необходимо переходить в дальнейшем, следующая инструкция должна будет пройти весь путь через конвейер перед тем, как результат становится доступным и процессор снова «работает». В крайнем случае, производительность конвейерного процессора может теоретически упасть до производительности бесконвейерного, или даже быть хуже за счет того, что будет занят только один уровень конвейера и между уровнями присутствует небольшая задержка.
Из-за конвейера процессора, код, который загружает процессор, не будет исполнен мгновенно. Из-за этого, обновления в коде, которые находятся очень близко к текущему месту исполнения программы, могут пройти незамеченными из-за того, что код уже предзагружен во входную очередь предвыборки (en:Prefetch input queue). Кэш инструкций ещё больше усугубляют эту проблему. Стоит учитывать, что данная проблема присутствует только в самомодифицирующихся программах, а также в упаковщиках исполняемых файлов.
См. также
Примечания
- ↑ «For the stall case, a bubble (NOP instruction) is sent to the next stage of pipeline and all previous stages stall for a time-step» // CPU — 32bit RISC
- ↑ «stream a pipeline bubble, or NOP, must be inserted» // Instruction Level Parallelism in VLIW Processors
- ↑ «Bubbles are NOP instructions» // Pipelined Processor Design
- ↑ The Linley Group - Best Extreme Processor: Xelerated X10q
Ссылки
- Воеводин Вл. В. Параллельная обработка данных (лекции). Раздел «Конвейерная обработка».
- Предсказание ветвлений в процессорах семейства Pentium (англ.)(недоступная ссылка — история)
- Статья по конвейерам (англ.) на ArsTechnica
- Архитектура процессора с противоточным конвейером (англ.)
- Влияние длины конвейера. Исследование эффективности ALU и FPU процессоров разных поколений от TestLabs.kz
Технологии цифровых процессоров Архитектура CISC · EDGE · EPIC · MISC · URISC · RISC · VLIW · ZISC · Фон Неймана · Гарвардская
8 бит · 16 бит · 32 бит · 64 бит · 128 битПараллелизм Pipeline Конвейер · In-Order & Out-of-Order execution · Переименование регистров · Speculative execution Уровни Бит · Инструкций · Суперскалярность · Данных · Задач Потоки Многопоточность · Simultaneous multithreading · Hyperthreading · Superthreading · Аппаратная виртуализация Классификация Флинна SISD · SIMD · MISD · MIMD Реализации DSP · GPU · SoC · PPU · Векторный процессор · Математический сопроцессор • Микропроцессор · Микроконтроллер Компоненты Barrel shifter · FPU · BSB · MMU · TLB · Регистровый файл · control unit · АЛУ • Демультиплексор · Мультиплексор · Микрокод · Тактовая частота • Корпус • Регистры • Кэш (Кэш процессора) Управление питанием APM · ACPI · Clock gating · Динамическое изменение частоты • Динамическое изменение напряжения Категории:- Технологии процессоров
- Обработка команд



Wikimedia Foundation. 2010.