- Кластеризация
-
Кластерный анализ (англ. Data clustering) — задача разбиения заданной выборки объектов (ситуаций) на непересекающиеся подмножества, называемые кластерами, так, чтобы каждый кластер состоял из схожих объектов, а объекты разных кластеров существенно отличались.
Задача кластеризации относится к статистической обработке, а также к широкому классу задач обучения без учителя.
Содержание
Типология задач кластеризации
Типы входных данных
- Признаковое описание объектов. Каждый объект описывается набором своих характеристик, называемых признаками. Признаки могут быть числовыми или нечисловыми.
- Матрица расстояний между объектами. Каждый объект описывается расстояниями до всех остальных объектов обучающей выборки.
Цели кластеризации
- Понимание данных путём выявления кластерной структуры. Разбиение выборки на группы схожих объектов позволяет упростить дальнейшую обработку данных и принятия решений, применяя к каждому кластеру свой метод анализа (стратегия «разделяй и властвуй»).
- Сжатие данных. Если исходная выборка избыточно большая, то можно сократить её, оставив по одному наиболее типичному представителю от каждого кластера.
- Обнаружение новизны (англ. novelty detection). Выделяются нетипичные объекты, которые не удаётся присоединить ни к одному из кластеров.
В первом случае число кластеров стараются сделать поменьше. Во втором случае важнее обеспечить высокую степень сходства объектов внутри каждого кластера, а кластеров может быть сколько угодно. В третьем случае наибольший интерес представляют отдельные объекты, не вписывающиеся ни в один из кластеров.
Во всех этих случаях может применяться иерархическая кластеризация, когда крупные кластеры дробятся на более мелкие, те в свою очередь дробятся ещё мельче, и т. д. Такие задачи называются задачами таксономии.
Результатом таксономии является древообразная иерархическая структура. При этом каждый объект характеризуется перечислением всех кластеров, которым он принадлежит, обычно от крупного к мелкому.
Классическим примером таксономии на основе сходства является биноминальная номенклатура живых существ, предложенная Карлом Линнеем в середине XVIII века. Аналогичные систематизации строятся во многих областях знания, чтобы упорядочить информацию о большом количестве объектов.
Методы кластеризации
- K-средних (
- Статистические алгоритмы кластеризации
- Алгоритм ФОРЕЛЬ
- Иерархическая кластеризация или таксономия
- Нейронная сеть Кохонена
- Ансамбль кластеризаторов
Формальная постановка задачи кластеризации
Пусть
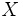 — множество объектов,
— множество объектов, 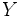 — множество номеров (имён, меток) кластеров. Задана функция расстояния между объектами
— множество номеров (имён, меток) кластеров. Задана функция расстояния между объектами 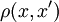 . Имеется конечная обучающая выборка объектов
. Имеется конечная обучающая выборка объектов 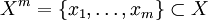 . Требуется разбить выборку на непересекающиеся подмножества, называемые кластерами, так, чтобы каждый кластер состоял из объектов, близких по метрике
. Требуется разбить выборку на непересекающиеся подмножества, называемые кластерами, так, чтобы каждый кластер состоял из объектов, близких по метрике 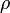 , а объекты разных кластеров существенно отличались. При этом каждому объекту
, а объекты разных кластеров существенно отличались. При этом каждому объекту 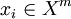 приписывается номер кластера
приписывается номер кластера 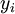 .
.Алгоритм кластеризации — это функция
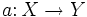 , которая любому объекту
, которая любому объекту 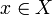 ставит в соответствие номер кластера
ставит в соответствие номер кластера 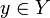 . Множество в некоторых случаях известно заранее, однако чаще ставится задача определить оптимальное число кластеров, с точки зрения того или иного критерия качества кластеризации.
. Множество в некоторых случаях известно заранее, однако чаще ставится задача определить оптимальное число кластеров, с точки зрения того или иного критерия качества кластеризации.Кластеризация (обучение без учителя) отличается от классификации (обучения с учителем) тем, что метки исходных объектов
изначально не заданы, и даже может быть неизвестно само множество .Решение задачи кластеризации принципиально неоднозначно, и тому есть несколько причин:
- не существует однозначно наилучшего критерия качества кластеризации. Известен целый ряд эвристических критериев,
а также ряд алгоритмов, не имеющих чётко выраженного критерия, но осуществляющих достаточно разумную кластеризацию «по построению». Все они могут давать разные результаты.
- число кластеров, как правило, неизвестно заранее и устанавливается в соответствии с некоторым субъективным критерием.
- результат кластеризации существенно зависит от метрики, выбор которой, как правило, также субъективен и определяется экспертом.
Применение
В биологии
В социологии
В информатике
- Группирование результатов поиска: Кластеризация используется для "интеллектуального" группирования результатов при поиске файлов, веб-сайтов, других объектов, предоставляя пользователю возможность быстрой навигации, выбора заведомо более релевантного подмножества и исключения заведомо менее релевантного — что может повысить юзабилити интерфейса по сравнению с выводом в виде простого сортированного по релевантности списка.
- Clusty[1] - кластеризующая поисковая машина компании Vivísimo
- поисковая система с автоматической кластеризацией результатов
- Сегментация изображений (image segmentation): Кластеризация может быть использована для разбиения цифрового изображения на отдельные области с целью обнаружения границ (edge detection) или распознавания объектов.
- Интеллектуальный анализ данных (data mining):Кластеризация в Data Mining приобретает ценность тогда, когда она выступает одним из этапов анализа данных, построения законченного аналитического решения. Аналитику часто легче выделить группы схожих объектов, изучить их особенности и построить для каждой группы отдельную модель, чем создавать одну общую модель для всех данных. Таким приемом постоянно пользуются в маркетинге, выделяя группы клиентов, покупателей, товаров и разрабатывая для каждой из них отдельную стратегию.
См. также
Литература
- Айвазян С. А., Бухштабер В. М., Енюков И. С., Мешалкин Л. Д. Прикладная статистика: классификация и снижение размерности. — М.: Финансы и статистика, 1989.
- Журавлев Ю. И., Рязанов В. В., Сенько О. В. «Распознавание». Математические методы. Программная система. Практические применения. — М.: Фазис, 2006. ISBN 5-7036-0108-8.
- Загоруйко Н. Г. Прикладные методы анализа данных и знаний. — Новосибирск: ИМ СО РАН, 1999. ISBN 5-86134-060-9.
- Мандель И. Д. Кластерный анализ. — М.: Финансы и статистика, 1988. ISBN 5-279-00050-7.
- Шлезингер М., Главач В. Десять лекций по статистическому и структурному распознаванию. — Киев: Наукова думка, 2004. ISBN 966-00-0341-2.
- Hastie T., Tibshirani R., Friedman J. The Elements of Statistical Learning. — Springer, 2001. ISBN 0-387-95284-5.
- Jain, Murty, Flynn Data clustering: a review. // ACM Comput. Surv. 31(3) , 1999
Внешние ссылки
На русском языке
- www.MachineLearning.ru — профессиональный вики-ресурс, посвященный машинному обучению и интеллектуальному анализу данных
- BaseGroup.ru: Кластеризация
- С. Николенко. Слайды лекций по алгоритмам кластеризации
На английском языке
- COMPACT - Comparative Package for Clustering Assessment. A free Matlab package, 2006.
- P. Berkhin, Survey of Clustering Data Mining Techniques, Accrue Software, 2002.
- Jain, Murty and Flynn: Data Clustering: A Review, ACM Comp. Surv., 1999.
- for another presentation of hierarchical, k-means and fuzzy c-means see this introduction to clustering. Also has an explanation on mixture of Gaussians.
- David Dowe, Mixture Modelling page - other clustering and mixture model links.
- a tutorial on clustering [2]
- The on-line textbook: Information Theory, Inference, and Learning Algorithms, by David J.C. MacKay includes chapters on k-means clustering, soft k-means clustering, and derivations including the E-M algorithm and the variational view of the E-M algorithm.
- An overview of non-parametric clustering and computer vision
- "The Self-Organized Gene", tutorial explaining clustering through competitive learning and self-organizing maps.
- kernlab - R package for kernel based machine learning (includes spectral clustering implementation)
- Tutorial - Tutorial with introduction of Clustering Algorithms (k-means, fuzzy-c-means, hierarchical, mixture of gaussians) + some interactive demos (java applets)
- Data Mining Software - Data mining software frequently utilizes clustering techniques.
- Java Competitve Learning Application A suite of Unsupervised Neural Networks for clustering. Written in Java. Complete with all source code.
- Machine Learning Software - Also contains much clustering software.
- Fuzzy Clustering Algorithms and their Application to Medical Image Analysis PhD Thesis, 2001, by AI Shihab.
- Cluster Computing and MapReduce Lecture 4
Wikimedia Foundation. 2010.