- Метод наименьших квадратов
-
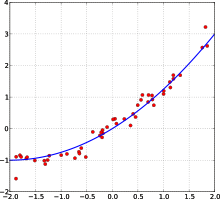 Пример кривой, проведённой через точки, имеющие нормально распределённое отклонение от истинного значения.
Пример кривой, проведённой через точки, имеющие нормально распределённое отклонение от истинного значения. Запрос «МНК» перенаправляется сюда; см. также другие значения.
Запрос «МНК» перенаправляется сюда; см. также другие значения.Метод наименьших квадратов (МНК, OLS, Ordinary Least Squares) — один из базовых методов регрессионного анализа для оценки неизвестных параметров регрессионных моделей по выборочным данным. Метод основан на минимизации суммы квадратов остатков регрессии.
Необходимо отметить, что собственно методом наименьших квадратов можно назвать метод решения задачи в любой области, если решение заключается или удовлетворяет некоторому критерию минимизации суммы квадратов некоторых функций от искомых переменных. Поэтому метод наименьших квадратов может применяться также для приближённого представления (аппроксимации) заданной функции другими (более простыми) функциями, при нахождении совокупности величин, удовлетворяющих уравнениям или ограничениям, количество которых превышает количество этих величин и т. д.
Содержание
Сущность МНК
Пусть задана некоторая (параметрическая) модель вероятностной (регрессионной) зависимости между (объясняемой) переменной y и множеством факторов (объясняющих переменных) x
где
 — вектор неизвестных параметров модели
— вектор неизвестных параметров модели — случайная ошибка модели.
— случайная ошибка модели.
Пусть также имеются выборочные наблюдения значений указанных переменных. Пусть
 — номер наблюдения (
— номер наблюдения ( ). Тогда
). Тогда  — значения переменных в -м наблюдении. Тогда при заданных значениях параметров b можно рассчитать теоретические (модельные) значения объясняемой переменной y:
— значения переменных в -м наблюдении. Тогда при заданных значениях параметров b можно рассчитать теоретические (модельные) значения объясняемой переменной y:Тогда можно рассчитать остатки регрессионной модели — разницу между наблюдаемыми значениями объясняемой переменной и теоретическими (модельными, оцененными):
Величина остатков зависит от значений параметров b.
Сущность МНК (обычного, классического) заключается в том, чтобы найти такие параметры b, при которых сумма квадратов остатков
 (англ. Residual Sum of Squares[1]) будет минимальной:
(англ. Residual Sum of Squares[1]) будет минимальной:где:
В общем случае решение этой задачи может осуществляться численными методами оптимизации (минимизации). В этом случае говорят о нелинейном МНК (NLS или NLLS — англ. Non-Linear Least Squares). Во многих случаях можно получить аналитическое решение. Для решения задачи минимизации необходимо найти стационарные точки функции
, продифференцировав её по неизвестным параметрам b, приравняв производные к нулю и решив полученную систему уравнений:Если случайные ошибки модели имеют нормальное распределение, имеют одинаковую дисперсию и некоррелированы между собой, МНК-оценки параметров совпадают с оценками метода максимального правдоподобия (ММП).
МНК в случае линейной модели
Пусть регрессионная зависимость является линейной:
Пусть y — вектор-столбец наблюдений объясняемой переменной, а
 — матрица наблюдений факторов (строки матрицы — векторы значений факторов в данном наблюдении, по столбцам — вектор значений данного фактора во всех наблюдениях). Матричное представление линейной модели имеет вид:
— матрица наблюдений факторов (строки матрицы — векторы значений факторов в данном наблюдении, по столбцам — вектор значений данного фактора во всех наблюдениях). Матричное представление линейной модели имеет вид:Тогда вектор оценок объясняемой переменной и вектор остатков регрессии будут равны
соответственно сумма квадратов остатков регрессии будет равна
Дифференцируя эту функцию по вектору параметров и приравняв производные к нулю, получим систему уравнений (в матричной форме):
 .
.
Решение этой системы уравнений и дает общую формулу МНК-оценок для линейной модели:
Для аналитических целей оказывается полезным последнее представление этой формулы. Если в регрессионной модели данные центрированы, то в этом представлении первая матрица имеет смысл выборочной ковариационной матрицы факторов, а вторая — вектор ковариаций факторов с зависимой переменной. Если кроме того данные ещё и нормированы на СКО (то есть в конечном итоге стандартизированы), то первая матрица имеет смысл выборочной корреляционной матрицы факторов, второй вектор — вектора выборочных корреляций факторов с зависимой переменной.
Немаловажное свойство МНК-оценок для моделей с константой — линия построенной регрессии проходит через центр тяжести выборочных данных, то есть выполняется равенство:
В частности, в крайнем случае, когда единственным регрессором является константа, получаем, что МНК-оценка единственного параметра (собственно константы) равна среднему значению объясняемой переменной. То есть среднее арифметическое, известное своими хорошими свойствами из законов больших чисел, также является МНК-оценкой — удовлетворяет критерию минимума суммы квадратов отклонений от неё.
Пример: простейшая (парная) регрессия
В случае парной линейной регрессии
 формулы расчета упрощаются (можно обойтись без матричной алгебры):
формулы расчета упрощаются (можно обойтись без матричной алгебры):Свойства МНК-оценок
В первую очередь, отметим, что для линейных моделей МНК-оценки являются линейными оценками, как это следует из вышеприведённой формулы. Для несмещенности МНК-оценок необходимо и достаточно выполнения важнейшего условия регрессионного анализа: условное по факторам математическое ожидание случайной ошибки должно быть равно нулю. Данное условие, в частности, выполнено, если
- математическое ожидание случайных ошибок равно нулю, и
- факторы и случайные ошибки — независимые случайные величины.
Первое условие можно считать выполненным всегда для моделей с константой, так как константа берёт на себя ненулевое математическое ожидание ошибок (поэтому модели с константой в общем случае предпочтительнее).
Второе условие — условие экзогенности факторов — принципиальное. Если это свойство не выполнено, то можно считать, что практически любые оценки будут крайне неудовлетворительными: они не будут даже состоятельными (то есть даже очень большой объём данных не позволяет получить качественные оценки в этом случае). В классическом случае делается более сильное предположение о детерминированности факторов, в отличие от случайной ошибки, что автоматически означает выполнение условия экзогенности. В общем случае для состоятельности оценок достаточно выполнения условия экзогенности вместе со сходимостью матрицы
 к некоторой невырожденной матрице при увеличении объёма выборки до бесконечности.
к некоторой невырожденной матрице при увеличении объёма выборки до бесконечности.Для того, чтобы кроме состоятельности и несмещенности, оценки (обычного) МНК были ещё и эффективными (наилучшими в классе линейных несмещенных оценок) необходимо выполнение дополнительных свойств случайной ошибки:
- Постоянная (одинаковая) дисперсия случайных ошибок во всех наблюдениях (отсутствие гетероскедастичности):

- Отсутствие корреляции (автокорреляции) случайных ошибок в разных наблюдениях между собой

Данные предположения можно сформулировать для ковариационной матрицы вектора случайных ошибок

Линейная модель, удовлетворяющая таким условиям, называется классической. МНК-оценки для классической линейной регрессии являются несмещёнными, состоятельными и наиболее эффективными оценками в классе всех линейных несмещённых оценок (в англоязычной литературе иногда употребляют аббревиатуру BLUE (Best Linear Unbaised Estimator) — наилучшая линейная несмещённая оценка; в отечественной литературе чаще приводится теорема Гаусса — Маркова). Как нетрудно показать, ковариационная матрица вектора оценок коэффициентов будет равна:

Эффективность означает, что эта ковариационная матрица является «минимальной» (любая линейная комбинация коэффициентов, и в частности сами коэффициенты, имеют минимальную дисперсию), то есть в классе линейных несмещенных оценок оценки МНК-наилучшие. Диагональные элементы этой матрицы — дисперсии оценок коэффициентов — важные параметры качества полученных оценок. Однако рассчитать ковариационную матрицу невозможно, поскольку дисперсия случайных ошибок неизвестна. Можно доказать, что несмещённой и состоятельной (для классической линейной модели) оценкой дисперсии случайных ошибок является величина:

Подставив данное значение в формулу для ковариационной матрицы и получим оценку ковариационной матрицы. Полученные оценки также являются несмещёнными и состоятельными. Важно также то, что оценка дисперсии ошибок (а значит и дисперсий коэффициентов) и оценки параметров модели являются независимыми случайными величинами, что позволяет получить тестовые статистики для проверки гипотез о коэффициентах модели.
Необходимо отметить, что если классические предположения не выполнены, МНК-оценки параметров не являются наиболее эффективными оценками (оставаясь несмещёнными и состоятельными). Однако, ещё более ухудшается оценка ковариационной матрицы — она становится смещённой и несостоятельной. Это означает, что статистические выводы о качестве построенной модели в таком случае могут быть крайне недостоверными. Одним из вариантов решения последней проблемы является применение специальных оценок ковариационной матрицы, которые являются состоятельными при нарушениях классических предположений (стандартные ошибки в форме Уайта и стандартные ошибки в форме Ньюи-Уеста). Другой подход заключается в применении так называемого обобщённого МНК.
Обобщенный МНК
Метод наименьших квадратов допускает широкое обобщение. Вместо минимизации суммы квадратов остатков можно минимизировать некоторую положительно определенную квадратичную форму от вектора остатков
 , где
, где  — некоторая симметрическая положительно определенная весовая матрица. Обычный МНК является частным случаем данного подхода, когда весовая матрица пропорциональна единичной матрице. Как известно из теории симметрических матриц (или операторов) для таких матриц существует разложение
— некоторая симметрическая положительно определенная весовая матрица. Обычный МНК является частным случаем данного подхода, когда весовая матрица пропорциональна единичной матрице. Как известно из теории симметрических матриц (или операторов) для таких матриц существует разложение  . Следовательно, указанный функционал можно представить следующим образом
. Следовательно, указанный функционал можно представить следующим образом  , то есть этот функционал можно представить как сумму квадратов некоторых преобразованных «остатков». Таким образом, можно выделить класс методов наименьших квадратов — LS-методы (Least Squares).
, то есть этот функционал можно представить как сумму квадратов некоторых преобразованных «остатков». Таким образом, можно выделить класс методов наименьших квадратов — LS-методы (Least Squares).Доказано (теорема Айткена), что для обобщенной линейной регрессионной модели (в которой на ковариационную матрицу случайных ошибок не налагается никаких ограничений) наиболее эффективными (в классе линейных несмещенных оценок) являются оценки т. н. обобщенного МНК (ОМНК, GLS — Generalized Least Squares) — LS-метода с весовой матрицей, равной обратной ковариационной матрице случайных ошибок:
 .
.Можно показать, что формула ОМНК-оценок параметров линейной модели имеет вид

Ковариационная матрица этих оценок соответственно будет равна

Фактически сущность ОМНК заключается в определенном (линейном) преобразовании (P) исходных данных и применении обычного МНК к преобразованным данным. Цель этого преобразования — для преобразованных данных случайные ошибки уже удовлетворяют классическим предположениям.
Взвешенный МНК
В случае диагональной весовой матрицы (а значит и ковариационной матрицы случайных ошибок) имеем так называемый взвешенный МНК (WLS — Weighted Least Squares). В данном случае минимизируется взвешенная сумма квадратов остатков модели, то есть каждое наблюдение получает «вес», обратно пропорциональный дисперсии случайной ошибки в данном наблюдении:
 . Фактически данные преобразуются взвешиванием наблюдений (делением на величину, пропорциональную предполагаемому стандартному отклонению случайных ошибок), а к взвешенным данным применяется обычный МНК.
. Фактически данные преобразуются взвешиванием наблюдений (делением на величину, пропорциональную предполагаемому стандартному отклонению случайных ошибок), а к взвешенным данным применяется обычный МНК.Некоторые частные случаи применения МНК на практике
Аппроксимация линейной зависимости

Рассмотрим случай, когда в результате изучения зависимости некоторой скалярной величины
 от некоторой скалярной величины
от некоторой скалярной величины  (Это может быть, например, зависимость напряжения
(Это может быть, например, зависимость напряжения  от силы тока
от силы тока  :
:  , где
, где  — постоянная величина, сопротивление проводника) было проведено
— постоянная величина, сопротивление проводника) было проведено  измерений этих величин, в результате которых были получены значения
измерений этих величин, в результате которых были получены значения  и соответствующие им значения
и соответствующие им значения  . Данные измерений должны быть записаны в таблице.
. Данные измерений должны быть записаны в таблице.Таблица. Результаты измерений.
№ измерения 1 

2 

3 

4 

5 

6 

Вопрос звучит так: какое значение коэффициента
 можно подобрать, чтобы наилучшим образом описать зависимость ? Согласно МНК это значение должно быть таким, чтобы сумма квадратов отклонений величин от величин
можно подобрать, чтобы наилучшим образом описать зависимость ? Согласно МНК это значение должно быть таким, чтобы сумма квадратов отклонений величин от величин 

была минимальной

Сумма квадратов отклонений имеет один экстремум — минимум, что позволяет нам использовать эту формулу. Найдём из этой формулы значение коэффициента
. Для этого преобразуем её левую часть следующим образом:
Далее идёт ряд математических преобразований:



Последняя формула позволяет нам найти значение коэффициента
, что и требовалось в задаче.История
До начала XIX в. учёные не имели определённых правил для решения системы уравнений, в которой число неизвестных меньше, чем число уравнений; до этого времени употреблялись частные приёмы, зависевшие от вида уравнений и от остроумия вычислителей, и потому разные вычислители, исходя из тех же данных наблюдений, приходили к различным выводам. Гауссу (1795) принадлежит первое применение метода, а Лежандр (1805) независимо открыл и опубликовал его под современным названием (фр. Méthode des moindres quarrés)[2]. Лаплас связал метод с теорией вероятностей, а американский математик Эдрейн (1808) рассмотрел его теоретико-вероятностные приложения[3]. Метод распространён и усовершенствован дальнейшими изысканиями Энке, Бесселя, Ганзена и других.
Альтернативное использование МНК
Идея метода наименьших квадратов может быть использована также в других случаях, не связанных напрямую с регрессионным анализом. Дело в том, что сумма квадратов является одной из наиболее распространенных мер близости для векторов (евклидова метрика в конечномерных пространствах).
Одно из применений — «решение» систем линейных уравнений, в которых число уравнений больше числа переменных
 ,
,где матрица
 не квадратная, а прямоугольная размера
не квадратная, а прямоугольная размера  .
.Такая система уравнений, в общем случае не имеет решения (если ранг
на самом деле больше числа переменных). Поэтому эту систему можно «решить» только в смысле выбора такого вектора , чтобы минимизировать «расстояние» между векторами  и
и  . Для этого можно применить критерий минимизации суммы квадратов разностей левой и правой частей уравнений системы, то есть
. Для этого можно применить критерий минимизации суммы квадратов разностей левой и правой частей уравнений системы, то есть  . Нетрудно показать, что решение этой задачи минимизации приводит к решению следующей системы уравнений
. Нетрудно показать, что решение этой задачи минимизации приводит к решению следующей системы уравненийИспользуя оператор псевдоинверсии, решение можно переписать так:
 ,
,
где
 — псевдообратная матрица для .
— псевдообратная матрица для .Данную задачу также можно «решить» используя взвешенный МНК, когда разные уравнения системы получают разный вес из теоретических соображений.
Естественно, данный подход может быть использован и в случае нелинейных систем уравнений.
Строгое обоснование и установление границ содержательной применимости метода даны А. А. Марковым и А. Н. Колмогоровым.
См. также
- Регрессионный анализ
- Метод наименьших модулей
- Обобщенный метод наименьших квадратов
- Рекурсивный МНК
- Метод инструментальных переменных
- Двухшаговый метод наименьших квадратов
Примечания
- ↑ Магнус, Катышев, Пересецкий, 2007, Обозначение RSS не унифицировано. RSS может быть сокращением от regression sum of squares, а ESS — error sum of squares, то есть, RSS и ESS будут иметь обратный смысл. с. 52. Издания 2004 года.
- ↑ Legendre, On Least Squares. Translated from the French by Professor Henry A. Ruger and Professor Helen M. Walker, Teachers College, Columbia University, New York City. (англ.)
- ↑ Александрова, 2008, с. 102
Литература
- Линник Ю. В. Метод наименьших квадратов и основы математико-статистической теории обработки наблюдений. — 2-е изд. — М., 1962. (математическая теория)
- Айвазян С. А. Прикладная статистика. Основы эконометрики. Том 2. — М.: Юнити-Дана, 2001. — 432 с. — ISBN 5-238-00305-6
- Доугерти К. Введение в эконометрику: Пер. с англ. — М.: ИНФРА-М, 1999. — 402 с. — ISBN 8-86225-458-7
- Кремер Н. Ш., Путко Б. А. Эконометрика. — М.: Юнити-Дана, 2003-2004. — 311 с. — ISBN 8-86225-458-7
- Магнус Я. Р., Катышев П. К., Пересецкий А. А. Эконометрика. Начальный курс. — М.: Дело, 2007. — 504 с. — ISBN 978-5-7749-0473-0
- Эконометрика. Учебник / Под ред. Елисеевой И. И. — 2-е изд. — М.: Финансы и статистика, 2006. — 576 с. — ISBN 5-279-02786-3
- Александрова Н. В. История математических терминов, понятий, обозначений: словарь-справочник. — 3-е изд.. — М.: ЛКИ, 2008. — 248 с. — ISBN 978-5-382-00839-4
Ссылки
- Теория и пример использования
- Метод наименьших квадратов. Аппроксимация зависимостей, отличных от линейных.
- Метод наименьших квадратов для зависимости y = a + bx на JavaScript.
- Метод наименьших квадратов онлайн для зависимости y = a + bx с вычислением погрешностей коэффициентов и оцениванием автокорреляции.
При написании этой статьи использовался материал из Энциклопедического словаря Брокгауза и Ефрона (1890—1907).
Для улучшения этой статьи желательно?: - Проставив сноски, внести более точные указания на источники.
- Переработать оформление в соответствии с правилами написания статей.
- Найти и оформить в виде сносок ссылки на авторитетные источники, подтверждающие написанное.
Категории:- Эконометрика
- Регрессионный анализ















Wikimedia Foundation. 2010.