- ЕМ
-
EM-алгоритм (англ. expectation-maximization) - алгоритм, используемый в математической статистике для нахождения оценок максимального правдоподобия параметров вероятностных моделей, в случае, когда модель зависит от некоторых скрытых переменных. Каждая итерация алгоритма состоит из двух шагов. На E-шаге (expectation) вычисляется ожидаемое значение функции правдоподобия, при этом скрытые переменные рассматриваются как наблюдаемые. На M-шаге (maximization) вычисляется оценка максимального правдоподобия, таким образом увеличивается ожидаемое правдоподобие, вычисляемое на E-шаге. Затем это значение используется для E-шага на следующей итерации. Алгоритм выполняется до сходимости.
Часто EM-алгоритм используют для разделения смеси гауссиан.
Описание алгоритма
Пусть
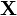 - некоторые из значений наблюдаемых переменных, а
- некоторые из значений наблюдаемых переменных, а 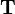 - скрытые переменные. Вместе и образуют полный набор данных. Вообще, может быть некоторой подсказкой, которая облегчает решение проблемы в случае, если она известна. Например, если имеется смесь распределений, функция правдоподобия легко выражается через параметры отдельных распределений смеси.
- скрытые переменные. Вместе и образуют полный набор данных. Вообще, может быть некоторой подсказкой, которая облегчает решение проблемы в случае, если она известна. Например, если имеется смесь распределений, функция правдоподобия легко выражается через параметры отдельных распределений смеси.Положим
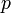 - плотность вероятности (в непрерывном случае) или функция вероятности (в дискретном случае) полного набора данных с параметрами Θ:
- плотность вероятности (в непрерывном случае) или функция вероятности (в дискретном случае) полного набора данных с параметрами Θ: 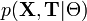 . Эту функцию можно понимать как правдоподобие всей модели, если рассматривать её как функцию параметров Θ. Заметим, что условное распределение скрытой компоненты при некотором наблюдении и фиксированном наборе параметров может быть выражено так:
. Эту функцию можно понимать как правдоподобие всей модели, если рассматривать её как функцию параметров Θ. Заметим, что условное распределение скрытой компоненты при некотором наблюдении и фиксированном наборе параметров может быть выражено так: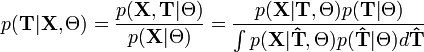 ,
,
используя расширенную формулу Байеса и формулу полной вероятности. Таким образом, нам необходимо знать только распределение наблюдаемой компоненты при фиксированной скрытой
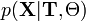 и вероятности скрытых данных
и вероятности скрытых данных 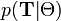 .
.EM-алгоритм итеративно улучшает начальную оценку Θ0, вычисляя новые значения оценок Θ1,Θ2, и так далее. На каждом шаге переход к
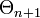 от
от 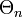 выполняется следующим образом:
выполняется следующим образом:- Θn + 1 = argmaxΘQ(Θ)
где Q(Θ) - матожидание логарифма правдоподобия. Другими словами, мы не можем сразу вычислить точное правдоподобие, но по известным данным (X) мы пожем найти апостериорную оценку вероятностей для различных значений скрытых переменных T. Для каждого набора значений T и параметров Θ мы можем вычислить матожидание функции правдоподобия по данному набору X. Оно зависит от предыдущего значения Θ, потому что это значение влияет на вероятности скрытых переменных T.
Q(Θ) вычисляется следующим образом:
то есть это условное матожидание
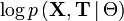 при условии Θ.
при условии Θ.Другими словами, Θn + 1 - это значение, маскимизирующее (M) условное матожидание (E) логарифма правдоподобия при данных значениях наблюдаемых переменных и предыдущем значении параметров. В непрерывном случае значение Q(Θ) вычисляется так:
Примеры использования
- кластеризации, построенный на идее EM-алгоритма
- Алгоритм Баума-Велша - алгоритм для оценки параметров скрытых марковских моделей
Ссылки
![Q(\Theta)
=
E_{\mathbf T} \! \! \left[ \log p \left(\mathbf X, \mathbf T \,|\, \Theta \right) \Big| \mathbf X \right]](/pictures/wiki/files/54/60f123b3fa790ee57aa6ce4d127ec688.png)
![Q(\Theta)
=
E_{\mathbf T} \! \! \left[ \log p \left(\mathbf X, \mathbf T \,|\, \Theta \right) \Big| \mathbf X \right]
=
\int^\infty _{- \infty}
p \left(\mathbf T \,|\, \mathbf X, \Theta_n \right)
\log p \left(\mathbf X, \mathbf T \,|\, \Theta \right) d\mathbf T](/pictures/wiki/files/99/cb82f442b18ee6fd25a81dffbd1ddf88.png)
Wikimedia Foundation. 2010.