- Сравнение алгоритмов выделения лиц
-
Содержание
Аннотация
Представлено описание трех современных алгоритмов обнаружения лиц на изображениях. Эти алгоритмы основаны на обучении классификаторов с помощью набора тренировочных изображений. Первый из описанных алгоритмов использует процедуру обучения, основанную на бустинге; второй – обучающую сеть SNoW (Sparse Network of Winnows); третий – обучение на базе машины опорных векторов (МОВ). Проведено сравнение описанных алгоритмов между собой. Представлен анализ работы тестируемых алгоритмов при наличии на изображениях искажений различного вида.
Введение
Система автоматического обнаружения лиц решает следующую задачу: по произвольному изображению на входе системы определить имеются ли на этом изображении лица, и если да, то указать, где находится каждое лицо и каков его размер. Алгоритмы выделения лиц находят применение в системах технического зрения, робототехнике, системах видеонаблюдения и контроля доступа, в интерфейсах взаимодействия человек-компьютер. Основными требованиями, которые предъявляются к подобному классу алгоритмов, являются: высокое качество распознавания, работа в режиме реального времени, робастность по отношению к внешним факторам [1-3]. Работа большинства алгоритмов выделения лиц на изображениях заключается в сканировании входного изображения окном, имеющим определенную форму и различный масштаб, и в определении к какому классу относится изображение внутри этого окна («лицо» либо «не лицо»). Таким образом, задача выделения лиц на изображениях сводится к построению классификатора, эффективно разделяющего классы «лиц» и «не лиц» [4].
За последние несколько лет было предложено множество алгоритмов обнаружения лиц, использующих различные подходы. Основные методы обнаружения лиц на изображениях можно разделить на четыре категории [5, 6].
Методы, основанные на знаниях
Сначала осуществляется поиск определенных черт лица (глаза, нос, рот) на входном изображении. Затем найденные кандидаты проверяются на соответствие закодированным законам, которые используют человеческие знания о том, что собой представляет типичное человеческое лицо. Законы описывают взаимозависимости между чертами лица, представленные их положением и расстоянием между ними. Например, лицо на изображении обычно имеет два глаза, расположенных симметрично относительно носа и рта.
Методы на основе инвариантных свойств
Эти алгоритмы стараются найти инвариантные свойства, которыми обладают области изображения, где находится лицо, даже при изменении условий освещения, выражения лица и его положения по отношению к камере. Сначала с помощью глобальных свойств, таких как цвет кожи, размер и форма лица, находятся кандидаты. Затем осуществляется проверка отобранных кандидатов с помощью таких черт лица как брови, глаза, нос, рот и волосы. Черты лица обычно находятся с помощью краевых детекторов.
Методы на основе сравнения с шаблоном
В этом случае выбирается несколько шаблонов лиц или отдельных черт лиц, чтобы в дальнейшем определить местонахождение лица, посчитав корреляции между входным изображением и этими шаблонами. Шаблоны лиц (обычно фронтальных) задаются вручную непосредственно или в виде параметров некоторой функции. Для того чтобы справляться с разнообразием форм и размеров, применяются масштабируемые, деформируемые шаблоны, шаблоны с переменным разрешением.
Методы на основе обучения
Алгоритмы на базе методов обучения используют математические модели, которые обучаются с помощью набора тренировочных изображений. Затем обученные модели используются для решения задачи обнаружения лиц на изображениях.
Методы, входящие в первые три категории, имеют существенные недостатки. Так, недостатком методов, основанных на знаниях, является то, что очень сложно преобразовать человеческие знания в хорошо определенные законы. Если составить очень детальные (строгие) законы, то система будет отбрасывать лица, которые не удовлетворяют им полностью. Если законы будут слишком общими, то это приведет к большому числу неверных обнаружений лиц. К тому же тяжело составить правила для обнаружения лиц в различных позах, поскольку необходимо предусмотреть все возможные случаи. Проблемой методов на базе неизменных характерных черт является то, что эти черты могут быть серьезно повреждены шумами, а также при засвечивании и затемнении изображения. Лицо может иметь еле заметную границу, в то время как тени могут дать многочисленные и четкие края, что приведет к некорректной работе алгоритма. Методы на основе сравнения с шаблоном демонстрируют низкий уровень выделения лиц, так как они не могут эффективно справляться с разнообразием форм, поз и размеров.
Методы на основе обучения лишены перечисленных выше недостатков, и поэтому считаются более эффективными. Среди них наибольшее распространение в настоящее время получили такие подходы как метод главных компонент, линейный дискриминантный анализ, искусственные нейронные сети, метод опорных векторов [5, 6].
Описание тестируемых алгоритмов
Для тестирования были выбраны три современных алгоритма выделения лиц на базе обучения. Первый алгоритм, предложенный П. Виолой и М. Джонсом в работе [7], использует процедуру обучения, основанную на бустинге. Второй алгоритм, описанный в работе [8], базируется на обучающей сети SNoW (Sparse Network of Winnows). Третий алгоритм, представленный в работе [9], основан на методе опорных векторов (МОВ). Рассмотрим подробнее структуру и принцип работы этих алгоритмов.
Алгоритм на базе бустинга
Данный алгоритм состоит из трех этапов:
Переход к интегральному изображению
Интегральное изображение позволяет быстро вычислять признаки изображения, которые используются классификатором. Основная причина использования признаков вместо значений пикселей в том, что признаки позволяют закодировать полученную в результате обучения информацию. К тому же системы, работающие с признаками гораздо быстрее систем, оперирующих со значениями пикселей. Предлагаемый алгоритм использует три вида простых признаков. Значение двух-прямоугольного признака вычисляется как разность между суммами значений пикселей, принадлежащих двум прямоугольным областям. Области имеют одинаковую длину и ширину и ориентированы вертикально или горизонтально, как показано на рисунке.
Значение трех-прямоугольного признака вычисляется как разность между суммой значений пикселей в двух внешних прямоугольниках и суммой значений пикселей в центральном прямоугольнике. И, наконец, четырех-прямоугольный признак находится как разность между суммами значений пикселей, расположенных в диагональных парах прямоугольников.Прямоугольные признаки могут быть быстро посчитаны с помощью промежуточного представления изображения, которое мы называем интегральным изображением. Интегральное изображение в точке (x,y) содержит сумму пикселей, расположенных слева и сверху над этой точкой, и определяется по формуле:
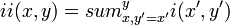 ,где ii(x,y) – интегральное изображение, i(x,y) – исходное изображение. Для вычисления используется следующая пара рекурсий:
,где ii(x,y) – интегральное изображение, i(x,y) – исходное изображение. Для вычисления используется следующая пара рекурсий:,
где – кумулятивная строка суммы, , . Следовательно, интегральное изображение может быть вычислено за один проход по первоначальному изображению. Используя интегральное изображение, вычисление признаков одинакового вида, но с разными геометрическими параметрами проходит за одинаковое время.
Метод построения классификатора на основе алгоритма бустинга
Сложный классификатор можно рассматривать как суперпозицию простых классификаторов порогового типа. Обозначим простой классификатор как: , ,
где – показывает направление знака неравенства, – значение порога, – вычисленное значение признака, – входное изображение, – общее количество признаков. Рассмотрим алгоритма бустинга [10], с помощью которого осуществляется отбор простых классификаторов и формирование на их основе сложного классификатора. Зададим обучающий набор , содержащий изображений лиц разрешением 24×24 пикселя и обучающий набор , содержащий изображений не лиц того же разрешения. Пусть , , где и – начальные веса для изображений обучающего набора «лиц» и «не лиц» соответственно. Тогда в цикле , где – число отбираемых простых классификаторов, произведем следующие операции: а) нормализация весов:
, ; , ;
б) вычисление ошибки классификации:
;
в) выбор классификатора с минимальной ошибкой:
,
где , и – параметры, при которых функция ошибки принимает минимальное значение;
г) адаптивное обновление весов: , ; , ;
где коэффициент обновления весов определяется по следующей формуле:
.
В результате работы алгоритма бустинга на каждой итерации формируется простой классификатор, который имеет минимальную ошибку по отношению к текущим значениям весов, задействованных в процедуре обучения для определения ошибки. После процедуры обновления весов, подчеркиваются те образцы, которые были неправильно классифицированы. Тем самым, на текущей итерации обучения следующий простой классификатор будет сформирован таким образом, чтобы не допустить ошибку на этих элементах обучающей выборки. На рис. 2 представлены первый и второй признаки, отобранные в результате работы алгоритма бустинга, на фоне окна детектора и на фоне типичного лица, используемого для обучения.
а) первый отобранный признак
б) второй отобранный признак Рис. 2. Первый и второй признаки, отобранные алгоритмом бустинга Первый отобранный признак основан на том свойстве, что область глаз чаще всего темнее области носа и щек. Этот признак имеет большой размер по сравнению с окном детектора, и потому не чувствителен к размеру и положению лица. Второй отобранный признак опирается на то, что глаза темнее спинки носа. Алгоритм использует окно детектора разрешением 24×24 пикселя и коэффициент масштабирования окна 1,25. Отобранные простые классификаторы формируют сложный классификатор по следующему правилу:
,
где – коэффициенты линейной комбинации, а – оптимальный порог классификатора, вычисляющиеся по формулам:
, .
Метод комбинирования классификаторов в каскадную структуру
Структура каскадного детектора приведена на рис. 3. Каскад состоит из слоев, которые представляют собой классификаторы, обученные с помощью процедуры бустинга [11, 12].
Рис. 3. Структура каскадного детектора
Процесс функционирования каскада происходит следующим образом: на вход каскада подается скользящее окно изображения, которое попадает на первый слой. Если текущий слой классифицирует окно как негативное, то происходит выход и анализ последующими слоями не выполняется. Если же текущий слой определяет окно как позитивное, то окно анализируется следующим слоем. Такой процесс происходит до тех пор, пока не будут пройдены все слои при позитивной классификации или не произойдет выход по негативному экземпляру. Учитывая тот факт, что на изображении количество фоновых скользящих окон во много раз превышает количество окон, на которых присутствуют лица, то выигрыш очевиден. Скорость обработки изображения при этом возрастает в 10-20 раз в зависимости от изображения, но при этом не теряется качество распознавания. При конструировании каскада, его структура определяется исходя из того, какие целевые требования к нему предъявляются. В результате обучения определяются следующие параметры каскада: количество слоев; количество простых классификаторов в каждом слое; пороговое значение каждого слоя. Задаются требуемые значения целевых параметров для каждого слоя. Каждый слой формируется с помощью процедуры бустинга, в процессе которой количество простых классификаторов увеличивается до тех пор, пока не будут достигнуты требуемые значения коэффициентов. Во время процедуры обучения данные разделяются на две выборки: обучающую и контрольную. Формирование простых классификаторов происходит с использованием обучающей выборки, а определение требуемых параметров – с использованием контрольной выборки. По ходу формирования слоев, каждый новый слой обучается на тех негативных экземплярах, которые были ошибочно классифицированы предыдущими слоями, благодаря этому каскад обладает высокими обобщающими способностями и низким коэффициентом ошибки.
Алгоритм на базе SNoW
Алгоритм на базе SNoW также можно условно разбить на три этапа:
Переход от значений пикселей к локальным SMQT признакам
SMQT [13] (Successive Mean Quantization Transform) – это преобразование, которое позволяет извлечь из локальной области изображения составляющую, не зависящую от освещенности. Оно заключается в квантовании области изображения с порогом квантования равным среднему значению пикселей, входящих в эту область. Локальная область может быть задана различными способами: как блок пикселей определенного разрешения; как набор интерполированных значений точек, находящихся на заданном расстоянии от фиксированного центра; либо каким-то другим произвольным образом. В любом случае, если обозначить значение одного пикселя как , то локальная область изображения может быть представлена в виде вектора , содержащего набор значений пикселей. Тогда результатом SMQT преобразования будет вектор той же размерности , содержащий новый набор значений. Вычисление вектора осуществляется в три этапа. Сначала находится среднее значение пикселей в области :
.
Затем производится операция квантования по следующему правилу:
.
В дальнейшем производится представление вектора в виде индекса:
.
Разработчики алгоритма задают локальную область как блок разрешением 3×3 пикселя. Для нахождения лиц на изображении используется окно детектора разрешением 32×32 пикселя. Сканирование осуществляется с шагом в один пиксель, как по горизонтали, так и по вертикали. Для того чтобы выделять лица разного размера, изображение многократно масштабируется с коэффициентом масштабирования 1,2. С целью избежания краевых эффектов при возможной фильтрации, к окну детектора применяется овальная маска, содержащая 648 пикселей (рис. 4). Каждому из этих 648 пикселей соответствует свой SMQT признак.
а) изображение из тренировочного набора
б) соответствующие этому изображению SMQT признаки Рис. 4. Маскировка пикселей изображения и соответствующих им SMQT признаков Переход к SMQT признакам позволяет алгоритму адаптироваться к изменению освещения объекта, так как SMQT признаки извлекают из изображения не зависящие от освещения компоненты.
Классификатор на базе обучающей сети SNoW
Обучающая архитектура SNoW (Sparse Network of Winnows) представляет собой разреженную сеть линейных элементов в пространстве признаков [14]. Большим достоинством сети SNoW является возможность создания весовых таблиц для классификации. Пусть – это набор SMQT признаков , тогда классификатор
может быть получен посредством использования весовой таблицы для не лиц и весовой таблицы для лиц , и определения порога для . Поскольку обе таблицы работают в одном домене, их можно объединить в одну весовую таблицу:
.
Для обучения классификатора использовалась база обучающих изображений лиц и не лиц. Изображения лиц были получены с помощью web-камеры. Далее на них вручную были отмечены три точки: правый глаз, левый глаз и центральная точка внешней границы верхней губы. После этого лицо деформировалось в блок 32×32 пикселя с различным расположением опорных точек (рис. 5).
Рис. 5. Получение набора обучающих изображений лицДеформация необходима для того, чтобы сымитировать различное положение лица по отношению к камере. В результате описанной процедуры был получен обучающий набор лиц емкостью порядка 1 миллиона образцов.
База обучающих изображений не лиц первоначально состояла из случайным образом сгенерированных изображений. После того как она была дополнена ошибками классификации, ее емкость также составила порядка 1 миллиона образцов. Каждому обучающему изображению соответствует набор SMQT признаков. Пусть тренировочная база состоит из наборов SMQT признаков и соответствующих каждому набору значений классов («лицо» или «не лицо»). Тогда весовые таблицы лиц и не лиц могут быть обучены с помощью закона обновления весов, получившего название Winnow Update Rule [15]. Изначально обе таблицы содержат нули. При первом обращении к элементу таблицы в процессе обучения ему присваивается значение 1. Три параметра системы задаются вручную: порог , повышающий коэффициент и понижающий коэффициент . Их значения были заданы следующим образом: , , . Если и – лицо, то веса обновляются согласно формуле:
.
Если и – лицо, то значение весов уменьшается:
.
Эта процедура повторяется до достижения неизменного значения весов. Обучение весовой таблицы для не лиц происходит точно таким же образом. И, наконец, общая весовая таблица находится по формуле .
Организация каскадной структуры
С целью увеличения быстродействия алгоритма полный классификатор SNoW разбивается на более слабые классификаторы, которые организуются в каскадную структуру (алгоритм Split-up SNoW). При этом не требуется дополнительного обучения слабых классификаторов. Пусть все возможные значения одного признака ограничиваются множеством , тогда вклад каждого признака в разделение классов можно оценить по формуле:
Отсортировав признаки по соответствующим им значениям , можно получить рейтинг лист признаков (importance list). Пусть – это подпространство, содержащее определенное количество признаков с наибольшим рейтингом. Тогда:
можно определить как слабый классификатор, который выделяет все лица из тренировочной базы, но имеет больший по сравнению с полным классификатором уровень неверного выделения. Увеличить количество слабых классификаторов в каскаде можно за счет тех же самых операций, выбирая подпространства следующим образом: . Разбиения происходят при 20, 50, 100, 200 и 648 признаках (рис. 6).
Рис 6. Каскадная структура алгоритма на базе SNoW Каскад состоит из 5 слоев. Признаки в каждый слой каскада отбираются согласно их рейтингу (importance list). Каждый слой отбирает кандидатов для следующего слоя и передает следующему слою значения уже посчитанных для этих кандидатов SMQT признаков.Алгоритм на базе МОВ
Этот алгоритм также удобно разбить на три этапа:
Построение классификатора на базе метода опорных векторов (МОВ)
Применение метода опорных векторов [16] к задаче обнаружения лиц заключается в поиске оптимальной гиперплоскости в признаковом пространстве, отделяющей класс изображений лиц от изображений не лиц. В качестве признаков служат значения пикселей изображения, представленные в виде n-мерного вектора. Оптимальной считается гиперплоскость, которая максимизирует ширину полосы между классами (рис. 7).
Рис. 7. Пример разделяющей полосы классификатора на базе МОВ Разделяющая гиперплоскость определяется как линейная комбинация небольшого набора тренировочных векторов, называемых опорными векторами. Обозначим набор собственных векторов как , а соответствующие им коэффициенты линейной комбинации – . МОВ – это линейный классификатор, поэтому для разделения линейно неразделимых классов применяется неявное проецирование векторов-признаков в пространство потенциально намного более высокой размерности (еще выше, чем пространство изображений), в котором классы могут оказаться линейно разделимыми (рис.8).
Рис. 8. Пример разделения линейно неразделимых классов с помощью перехода к пространству более высокой размерности Проецирование осуществляется с помощью аппарата ядерных функций. Неявное проецирование с помощью ядерных функций не приводит к усложнению вычислений, что позволяет успешно использовать линейный классификатор для линейно неразделимых классов. Формально решающее правило классификатора на базе МОВ для входного изображения может быть записано следующим образом:
,
где – это ядерная функция, а – смещение. Для нахождения разделяющей гиперплоскости использовался тренировочный набор, содержащий около 13 тысяч изображений лиц с разрешением 19×19 пикселей и около 36 тысяч изображений не лиц. Для увеличения размера окна детектора применялось масштабирование с коэффициентом 3/4. В качестве ядерной функции использовалась радиальная базисная функция Гаусса при . Обученный классификатор содержал опорных векторов.
Вычисление аппроксимаций для классификатора МОВ
Для ускорения принятия решения обученный классификатор на базе МОВ, содержащий опорных векторов, аппроксимируется классификатором с меньшим набором опорных векторов , где . При этом быстродействие алгоритма увеличивается в раз [17,18]. Решающее правило такого классификатора определяется по формуле:
.
Для нахождения и необходимо решить уравнение
.
На практике и находятся при помощи градиентного метода оптимизации [19].
Комбинирование классификаторов в каскадную структуру
С целью увеличения быстродействия алгоритма и уменьшения ошибки классификации классификатор SVM организуется в каскадную структуру, аналогичную каскадной структуре алгоритма на базе SNoW (рис. 9).
Рис 9. Каскадная структура алгоритма на базе SVM Каскад состоит из 5 слоев, в которых классификатор МОВ аппроксимируется уменьшенным набором из 3, 4, 8, 16 и 32 опорных векторов соответственно.Результаты тестирования
Для проведения экспериментов была составлена база данных из 50 цветных изображений, разрешения 768×576 пикселей, суммарно содержащая 213 лиц. На рис. 10 представлены примеры изображений из этой базы, на которых с помощью тестируемых алгоритмов были выделены лица.

а)
б)
в)
Рис. 10. Примеры изображений, обработанных с помощью: а) алгоритма на базе бустинга; б) алгоритма на базе SNoW; в) алгоритма на базе МОВ Приведенные примеры иллюстрируют два типа ошибок, возникающих в результате работы системы выделения лиц: не выделение лица и ложное обнаружение (выделение объекта, который лицом не является). В связи с наличием двух типов ошибок, существует два основных параметра, характеризующих эффективность работы алгоритмов обнаружения лиц: уровень выделения (detection rate), показывающий процент обнаруженных лиц, и уровень неверного выделения (false positive rate), равный общему числу ложных обнаружений на всем тестовом наборе. Из рис. 10 видно, что одно и то же лицо, выделенное разными алгоритмами, имеет разный размер. Так алгоритм на базе бустинга выделяет лицо полностью, захватывая лоб, подбородок и щеки. Алгоритмы на базе SNoW и МОВ выделяют только глаза, нос и рот, причем алгоритм на базе МОВ выделяет лицо более узким окном. Эти различия вызваны тем, что в процессе создания алгоритмов использовались различные наборы обучающих изображений для построения классификатора. Следует отметить, что алгоритм на базе бустинга более адекватно отображает истинный размер лица. Далее представлены результаты сравнения тестируемых алгоритмов между собой по двум параметрам: уровню выделения и уровню неверного выделения. В процессе сравнения исследовалась робастность тестируемых алгоритмов к различным видам искажений на изображении. На рис. 11 приведена зависимость уровня выделения от среднеквадратичного отклонения (СКО) гауссова шума, а в табл. 1 представлен уровень неверного выделения при различных значениях СКО.
Рис. 11. Зависимость уровня выделения от СКО гауссова шума
Таблица 1 Уровень неверного выделения при различных СКО гауссова шума СКО Тестируемые алгоритмы 0 10 20 30 40 50 60 70 80 90 100 Бустинг 39 31 39 25 28 29 33 31 28 20 28 SNoW 34 73 57 46 35 25 23 14 21 13 18 МОВ 73 75 52 43 24 22 19 20 15 11 16
На наборе неискаженных изображений лучший результат по уровню выделения показал алгоритм на базе SNoW – 87,3%. Алгоритм на базе бустинга отстал от лидера на 4,7% и показал уровень выделения – 82,6%. Алгоритм на базе МОВ значительно отстает от других алгоритмов, его уровень выделения – 62,4%. При этом меньше всего ложных обнаружений допустил алгоритм на базе SNoW, чуть больше ошибался алгоритм на базе бустинга, и в два раза больше ложных обнаружений у алгоритма на базе МОВ. При внесении гауссова шума уровень выделения алгоритма на базе SNoW резко уменьшается. При алгоритм на базе SNoW занимает второе место по уровню выделения, уступая алгоритму на базе бустинга, а при – последнее место. Это связано с тем, что алгоритм на базе SNoW использует 3×3 SMQT признаки, значение которых при внесении шума становится случайным. Уровень выделения алгоритма на базе МОВ убывает практически линейно. Наибольшую же устойчивость к внесению гауссова шума продемонстрировал алгоритм на базе бустинга. Это объясняется тем, что алгоритм использует прямоугольные признаки, значение которых при внесении шума изменяется незначительно – на разность средних значений шума в двух прямоугольных областях. По среднему уровню выделения лидирует алгоритм на базе бустинга – 70,2%. На втором и третьем месте алгоритмы на базе МОВ и SNoW – 37,2% и 32,6% соответственно. Уровень неверного выделения алгоритма на базе бустинга при внесении гауссова шума изменяется незначительно. У алгоритма на базе SNoW наблюдается всплеск уровня неверного выделения при СКО = 10, а затем его уменьшение при дальнейшем увеличении СКО. Уровень неверного выделения алгоритма на базе МОВ при внесении шума уменьшается. Тенденция к уменьшению числа ложных обнаружений вызвана тем, что структура зашумленной области изображения не похожа на структуру лица. Перейдем к рассмотрению ситуации наличия импульсного шума типа «соль-и-перец» (рис. 12, табл. 2).
Рис. 12. Зависимость уровня выделения от вероятности импульсного шума Таблица 2 Уровень неверного выделения для различных значений вероятности импульсного шума
Тестируемые алгоритмы 0 10 20 30 40 50 60 70 80 90 100 Бустинг 39 34 36 26 28 27 30 20 22 28 23 SNoW 34 10 9 4 3 6 5 2 4 4 4 МОВ 73 39 24 18 6 11 6 10 8 4 2
При внесении импульсного шума сохраняются тенденции, описанные ранее. Алгоритм на базе SNoW не способен справится с импульсным шумом, так как попадание импульса в область по которой высчитывается SMQT признак, приводит к полной потере информации. Уровень выделения алгоритма на базе МОВ, использующего непосредственно значения пикселей, при внесении импульсного шума также быстро уменьшается. Импульсный шум более критичен, чем гауссов и для алгоритма на базе бустинга. По среднему уровню выделения лидирует алгоритм на базе бустинга – 57,8%. На втором и третьем месте алгоритмы на базе SNoW и МОВ – 23,8% и 22,7% соответственно. Уровень неверного выделения всех трех алгоритмов при внесении импульсного шума уменьшается, так как импульсный шум делает объекты более непохожими на лица. Быстрее всех убывает уровень неверного выделения алгоритма на базе SNoW, поскольку он менее всех устойчив к внесению импульсного шума. Помимо появления на изображении различных шумовых пикселей оно может также подвергаться размытию. Степень размытия изображения будем характеризовать с помощью универсального индекса качества (УИК) [20]. Чем сильнее размыто изображение, тем меньше значения данного критерия. Для исходного изображения он принимает значение 1, а при сильном размытии его значения приближаются к нулю. Зависимости уровня выделения и уровня неверного выделения для различных значений УИК размытого изображения приведены на рис. 13 и в табл. 3.
Рис. 13. Зависимость уровня выделения от степени размытия изображения Таблица 3 Уровень неверного выделения для различных значений УИК УИК Тестируемые алгоритмы 1 0,736 0,501 0,367 0,290 0,244 0,214 0,192 Бустинг 39 39 35 30 29 25 15 10 SNoW 34 81 125 147 140 120 102 90 МОВ 73 129 137 119 85 74 58 55
В отличие от ситуации добавления шума, небольшое размытие изображения не приводит к резкому уменьшению уровня выделения лиц. При изменении УИК от 1 до 0,6 уровень выделения тестируемых алгоритмов уменьшается менее чем на 10%. И только при сильном размытии происходит резкое уменьшение уровня выделения. Наибольшую устойчивость к размытию демонстрирует алгоритм на базе SNoW. Это связано с тем, что процедура квантования с порогом квантования равным среднему значению в области изображения 3×3 пикселя, используемая для вычисления SMQT признаков, способствует частичному восстановлению информации о структуре этой области. При всех значениях УИК по уровню выделения лидирует алгоритм на базе SNoW. Его средний уровень выделения составил 77,9%. На втором месте алгоритм на базе бустинга со средним уровнем выделения – 71,3%. Худший результат показал алгоритм на базе МОВ – 54,3%. Размытие приводит к сильному всплеску количества ложных обнаружений алгоритмов на базе SNoW и МОВ. Плавное изменение значений пикселей воспринимается этими алгоритмами как лицо. Только алгоритм на базе бустинга сохраняет способность разделять классы лиц и не лиц. Его уровень неверного выделения при увеличении степени размытия уменьшается. Последний вид искажений, который был рассмотрен – это сжатие изображения с использованием алгоритма JPEG. Как известно, при сильном сжатии с помощью этого алгоритма на изображении проявляется блочная структура. Рассмотрим, каким образом подобные искажения влияют на работу алгоритмов выделения лиц. Зависимости уровня выделения и уровня неверного выделения от коэффициента сжатия представлены на рис. 14 и в табл. 4.
Рис. 14. Зависимость уровня выделения от коэффициента сжатия изображения Таблица 4 Уровень неверного выделения для различных значений коэффициента сжатия
Тестируемые алгоритмы 0 20 40 60 80 100 120 140 Бустинг 39 30 46 32 23 24 14 15 SNoW 34 32 14 12 6 6 1 0 МОВ 73 84 89 93 108 99 114 89 Небольшое сжатие слабо влияет на уровень выделения лиц. Лишь при проявляется блочная структура изображения, и уровень выделения тестируемых алгоритмов начинает уменьшаться. Наименьшую устойчивость к артефактам сжатия показал алгоритм на базе SNoW. Дополнительные границы, появляющиеся при сжатии, приводят к изменению значений SMQT признаков. В результате алгоритм на базе SNoW теряет способность выделять лица. Алгоритм на базе бустинга, наоборот, демонстрирует высокую устойчивость к артефактам сжатия, так как он использует информацию, которая менее всего подвержена разрушению при сжатии изображения – информацию о среднем значении пикселей в прямоугольной области. По среднему уровню выделения лидирует алгоритм на базе бустинга – 72,5%. На втором и третьем месте алгоритмы на базе SNoW и МОВ – 52,5% и 50,6% соответственно. Уровень неверного выделения алгоритма на базе SNoW при увеличении коэффициента сжатия уменьшается. Число ложных обнаружений алгоритма на базе бустинга, хотя и имеет небольшой всплеск при , также имеет тенденцию уменьшения с увеличением сжатия. Алгоритм на базе МОВ воспринимает блочную структуру как лицо. Его уровень неверного выделения при сжатии изображения увеличивается.
Заключение
Проведено сравнение трех современных алгоритмов выделения лиц на изображениях на базе обучения. Это алгоритмы на базе процедуры бустинга, на базе обучающей сети SNoW, и на базе метода опорных векторов (МОВ). Лучший результат по уровню выделения лиц на неискаженных изображениях показал алгоритм на базе SNoW – 87,3%. На втором и третьем местах алгоритмы на базе бустинга (82,6%) и МОВ (62,4%) соответственно. Исследовано влияние на работу тестируемых алгоритмов нескольких типов искажений: гауссов шум, импульсный шум, размытие и сжатие JPEG. Результаты проведенных экспериментов показали, что алгоритм на базе бустинга более устойчив к искажениям всех типов. Он значительно превосходит другие тестируемые алгоритмы по среднему уровню выделения при внесении гауссова и импульсного шумов (≈ на 33%), а также при сжатии JPEG (≈ на 20%). При размытии алгоритм на базе бустинга уступает по среднему уровню выделения 6,6% алгоритму на базе SNoW, однако при этом он допускает в 4 раза меньше ошибок классификации.
Литература
- Гонсалес Р., Вудс Р. Цифровая обработка изображений – М.: Техносфера, 2005.
- Методы компьютерной обработки изображений / Под ред. В.А. Сойфера. – М.: Физматлит, 2001.
- Форсайт Д.А., Понс Д. Компьютерное зрение. Современный подход – М.: «Вильямс», 2004.
- Потапов А.С. Распознавание образов и машинное восприятие: общий подход на основе принципа минимальной длины описания. - СПб.: Политехника. — 2007.
- Kriegman D., Yang M.H., Ahuja N. Detecting faces in images: A survey // IEEE Transactions on Pattern Analysis and Machine Intelligence. 2002. V. 24 № 1. P. 34-58.
- Hjelmas E. Face detection: A Survey // Computer vision and image understanding. 2001. V. 83, № 3. P. 236-274.
- Viola P., Jones M. Rapid object detection using a boosted cascade of simple features // Proc. Int. Conf. on Computer Vision and Pattern Recognition. 2001. № 1. P. 511-518.
- Nilsson M., Nordberg J., Claesson I. Face Detection Using Local SMQT Features and Split Up SNoW Classifier // Proceedings of IEEE Int. Conf. ICASSP 2007, V. 2, P. 589 -592.
- Kienzle W., Bakir G., Franz M., Schölkopf B. Face Detection - Efficient and Rank Deficient // Adv. in Neural Inf. Proc. Systems, V.17, P. 673 - 680, 2005.
- Freund Y., Schapire R. A decision-theoretic generalization of on-line learning and an application to boosting // Computational Learning Theory: Eurocolt ’95. 1995. P. 23-37.
- Jordan M.I., Jacobs R.A. Hierarchical mixtures of experts and the EM algorithm // Neural Computation. 1994. № 6. P. 181-214.
- Miller D., Uyar H. A mixture of experts classifier with learning based on both labeled and unlabeled data // Neural information processing systems. 1996. № 9. P. 571-577.
- Nilsson M., Dahl M., Claesson I. The successive mean quantization transform // Proceedings of IEEE Int. Conf. ICASSP, V. 4, P. 429 - 432, 2005.
- D. Roth. The SNoW Learning Architecture // Technical Report UIUCDCS-R-99-2102, UIUC Computer Science Department, 1999.
- D. Roth, M.-H. Yang, and N. Ahuja. A SNoW-based face detector // in Advances in Neural Information Processing Systems 12 (NIPS 12), MIT Press, Cambridge, MA, pp. 855-861, 2000.
- E. Osuna, R. Freund, and F. Girosi. Training support vector machines: an application to face detection // In Proceedings IEEE Conference on Computer Vision and Pattern Recognition, 1997.
- E. Osuna and F. Girosi. Reducing the run-time complexity in support vector machines // Advances in Kernel Methods—Support Vector Learning, pp. 271–284, Cambridge, MA, 1999. MIT Press.
- C. J. C. Burges and B. Schölkopf. Improving the accuracy and speed of support vector machines // Advances in Neural Information Processing Systems, volume 9, page 375. MIT Press, 1997.
- C. J. C. Burges. Simplified support vector decision rules // In International Conference on Machine Learning, pages 71–77, 1996.
- Арляпов С.А., Приоров А.Л., Хрящев В.В. Модифицированный критерий оценки качества восстановленных изображений // Цифровая обработка сигналов. 2006. № 2. С. 27-33.
Wikimedia Foundation. 2010.