- k-means
-
k-means (метод k-средних) — наиболее популярный метод кластеризации. Был изобретён в 1950-х годах математиком Гуго Штейнгаузом[1] и почти одновременно Стюартом Ллойдом[2]. Особую популярность приобрёл после работы Маккуина[3].
Действие алгоритма таково, что он стремится минимизировать суммарное квадратичное отклонение точек кластеров от центров этих кластеров:
где
 — число кластеров,
— число кластеров,  — полученные кластеры,
— полученные кластеры,  и
и  — центры масс векторов
— центры масс векторов  .
.По аналогии с методом главных компонент центры кластеров называются также главными точками, а сам метод называется методом главных точек[4] и включается в общую теорию главных объектов, обеспечивающих наилучшую аппроксимацию данных[5].
Содержание
Алгоритм
Алгоритм представляет собой версию EM-алгоритма, применяемого также для разделения смеси гауссиан. Он разбивает множество элементов векторного пространства на заранее известное число кластеров k.
Основная идея заключается в том, что на каждой итерации перевычисляется центр масс для каждого кластера, полученного на предыдущем шаге, затем векторы разбиваются на кластеры вновь в соответствии с тем, какой из новых центров оказался ближе по выбранной метрике.
Алгоритм завершается, когда на какой-то итерации не происходит изменения кластеров. Это происходит за конечное число итераций, так как количество возможных разбиений конечного множества конечно, а на каждом шаге суммарное квадратичное уклонение V уменьшается, поэтому зацикливание невозможно.
Как показали Дэвид Артур и Сергей Васильвицкий на некоторых классах множеств сложность алгоритма по времени, нужному для сходимости, равна
 .[6]
.[6]Демонстрация алгоритма
Действие алгоритма в двумерном случае. Начальные точки выбраны случайно.
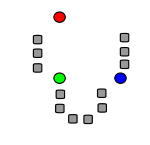 Исходные точки и случайно выбранные начальные точки.
Исходные точки и случайно выбранные начальные точки.
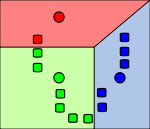 Точки, отнесённые к начальным центрам. Разбиение на плоскости — диаграмма Вороного относительно начальных центров.
Точки, отнесённые к начальным центрам. Разбиение на плоскости — диаграмма Вороного относительно начальных центров. Вычисление новых центров кластеров (Ищется центр масс).
Вычисление новых центров кластеров (Ищется центр масс). Предыдущие шаги повторяются, пока алгоритм не сойдётся.
Предыдущие шаги повторяются, пока алгоритм не сойдётся.Проблемы k-means
 Типичный пример сходимости метода k средних к локальному минимуму. В этом примере результат "кластеризации" методом k средних противоречит очевидной кластерной структуре множества данных. Маленькими кружками обозначены точки даных, четырехлучевые звезды - центроиды. Принадлежащие им точки данных окрашены в тот же цвет. Иллюстрация подготовлена с помощью апплета Миркеса[7].
Типичный пример сходимости метода k средних к локальному минимуму. В этом примере результат "кластеризации" методом k средних противоречит очевидной кластерной структуре множества данных. Маленькими кружками обозначены точки даных, четырехлучевые звезды - центроиды. Принадлежащие им точки данных окрашены в тот же цвет. Иллюстрация подготовлена с помощью апплета Миркеса[7].- Не гарантируется достижение глобального минимума суммарного квадратичного отклонения V, а только одного из локальных минимумов.
- Результат зависит от выбора исходных центров кластеров, их оптимальный выбор неизвестен.
- Число кластеров надо знать заранее.
Расширения и вариации
Широко известна и используется нейросетевая реализация K-means — сети векторного квантования сигналов (одна из версий нейронных сетей Кохонена).
Существует расширение k-means++, которое направлено на оптимальный выбор начальных значений центров кластеров.
Ссылки
- ↑ Steinhaus H. (1956). Sur la division des corps materiels en parties. Bull. Acad. Polon. Sci., C1. III vol IV: 801—804.
- ↑ Lloyd S. (1957). Least square quantization in PCM’s. Bell Telephone Laboratories Paper.
- ↑ MacQueen J. (1967). Some methods for classification and analysis of multivariate observations. In Proc. 5th Berkeley Symp. on Math. Statistics and Probability, pages 281—297.
- ↑ Flury B. (1990). Principal points. Biometrika, 77, 33-41.
- ↑ Gorban A.N., Zinovyev A.Y. (2009). Principal Graphs and Manifolds, Ch. 2 in: Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques, Emilio Soria Olivas et al. (eds), IGI Global, Hershey, PA, USA, pp. 28-59.
- ↑ David Arthur & Sergei Vassilvitskii (2006). "How Slow is the k-means Method?". Proceedings of the 2006 Symposium on Computational Geometry (SoCG).
- ↑ E.M. Mirkes, K-means and K-medoids applet. University of Leicester, 2011.
Демонстрация и визуализация
- K-means and K-medoids (апплет, демонстрирующий работу алгоритма и позволяющий исследовать и сравнивать два метода), Е. Миркес и University of Leicester
- Интерактивный апплет, демонстрирующий работу алгоритма
 Категории:
Категории:- Машинное обучение
- Кластерный анализ
-






Wikimedia Foundation. 2010.