- Silent Speech Interfaces
-

Эта статья или раздел нуждается в переработке. Пожалуйста, улучшите статью в соответствии с правилами написания статей.Silent Speech Interfaces (сокр. SSI; интерфейсы безмолвного доступа) — системы обработки речи, базирующиеся на получении и обработке речевых сигналов на ранней стадии артикулирования.
В прошлом десятилетии работа автоматических систем обработки речи, в том числе распознавание речи, текста, перевода и синтеза речи значительно улучшилась. Это привело к использованию речи и речевых технологий в широком спектре услуг, таких как информационно-поисковые системы, колл-центры, голосовое управление мобильными телефонами и автомобильными навигационными системами, персональные переводчики, а также к применению речевых технологий в области безопасности. Тем не менее речевые интерфейсы, базирующиеся на традиционных акустических речевых сигналах, все еще имеют ряд существенных ограничений. Во-первых, акустические сигналы, передаваемые через воздух, подвержены искажениям из-за шумов. Надежных систем обработки речи, которые бы безукоризненно функционировали в переполненных ресторанах, аэропортах и других общественных местах, несмотря на титанические усилия, по-прежнему не видно. Во-вторых, традиционные речевые интерфейсы требуют чётко и внятно произносимой речи, что имеет два основных недостатка: в общественном месте она ставит под угрозу конфиденциальность сообщения и, второе, беспокоит окружающих. Услуги, которые требуют доступа, поиска и передачи частной или конфиденциальной информации, такой, как PIN-коды, пароли — особенно уязвимы.
Недавно для решения этой проблемы были предложены интерфейсы безмолвного доступа, которые позволяют пользователям совершать коммуникацию, говоря «безмолвно», то есть без произнесения каких-либо звуков. Это осуществляется путем получения речевых сигналов на ранних этапах человеческой артикуляции, а именно до того, как речь появится в воздухе; после этого артикуляционные сигналы передаются системе для дальнейшей обработки и интерпретации. В связи с этим новым подходом интерфейсы безмолвного доступа обладают потенциалом для преодоления основных недостатков сегодняшних традиционных речевых интерфейсов:
- ограничение надежности распознавания речевого сигнала при наличии фонового шума,
- отсутствие надежности при передаче частной и конфиденциальной информации,
- беспокойство окружающих.
Кроме того, интерфейсы безмолвного доступа могли бы стать альтернативой для людей с недостатками речи (например, ларингэктомия), а также для пожилых или ослабленных людей, которые не могут говорить достаточно громко, четко и разборчиво.
Интерфейсы безмолвного доступа имеют очень недавнюю историю. Chan и др. (2001, 2002) доказали, что миоэлектрический сигнал от артикуляционных лицевых мышц содержит достаточно информации, чтобы точно различать небольшой набор слов. Эти слова распознаются, даже когда их произносят негромко, то есть при отсутствии звукового сигнала (Jorgensen и др. 2003, Bradley и др. 2006). Последние работы свидетельствуют о том, что распознавание фонемных единиц на основе электромиографических (ЭМГ) единиц (Jou и др. 2006, Walliczek и др. 2006) открывают путь для распознавания обширных словарных баз. Также совсем недавно появились исследования, позволяющие с помощью ультразвуковых и оптических изображений разработать Интерфейс Безмолвного Доступа, основанный на движениях языка и губ (Denby и Stone 2004, Denby и др. 2006, Hueber и др. 2007). Системы SSI, позволяющие преобразовывать «бурчание» в речевой сигнал, преимущественно разрабатываются в Японии. В Соединенных Штатах DARPA финансирует исследования активности голосовой щели для использования датчиков в шумных условиях.


В рамках программы современного речевого кодирования (англ. Advanced speech encoding, сокр. ASE)[1] будут разрабатываться технологии, которые позволят обмениваться информацией в сложных военных условиях.
За последние 50 лет достигнуты большие успехи в развитии кодировщика голоса (вокодера), но, по-прежнему, ультранизкий битрейт (ULBR) голосового кодирования при 300 бит/с остается серьёзной проблемой. В частности ULBR-вокодеры до сих пор не имеют качественного анализатора речи, который бы без помех распознавал речь говорящего; эти недостатки гиперболизируются в акустически трудных средах (например, в шумном пространстве или в пространстве с отражающимся звуком).
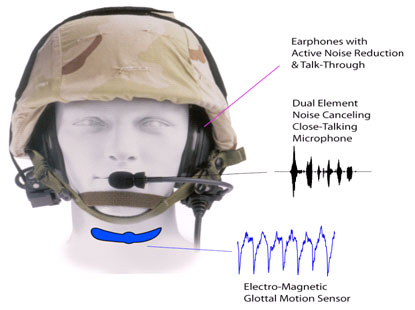
Подход, реализуемый в рамках программы современного речевого кодирования (ASE), заключается в том, чтобы использовать новые сенсоры, не подверженные влиянию шумов в качестве дополнения к обработанным акустическим сигналам (см. рис.). Такие датчики будут изучены в отношении их потенциала, с тем чтобы доречевой/дослышимый режим речи мог быть использован в качестве альтернативных средств коммуникации в акустически суровых и опасных условиях, в которых военная маскировка оказывается обязательной.
—
Примечания
- ↑ Advanced speech encoding. Virtual worldlets network.
Ссылки
Категории:- Интерфейс пользователя
- Речевая коммуникация
- Распознавание речи
Wikimedia Foundation. 2010.