- КОДИРОВАНИЕ ИНФОРМАЦИИ
- КОДИРОВАНИЕ ИНФОРМАЦИИ
-
- установление соответствия между элементами сообщения и сигналами, при помощи к-рых эти элементы могут быть зафиксированы.
Пусть В,
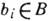 ,
,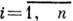 - множество элементов сообщения, А - алфавит с символами
- множество элементов сообщения, А - алфавит с символами 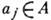 ,
,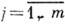 Пусть конечная последовательность символов наз. словом в данном алфавите. Множество слов в алфавите А наз. кодом, если оно поставлено во взаимно однозначное соответствие с множеством В. Каждое слово, входящее в код, наз. кодовым словом. Число символов в кодовом слове наз. длиной слова. Кодовые слова могут иметь одинаковую или разл. длину. В соответствии с этим код наз. равномерным или неравномерным.
Пусть конечная последовательность символов наз. словом в данном алфавите. Множество слов в алфавите А наз. кодом, если оно поставлено во взаимно однозначное соответствие с множеством В. Каждое слово, входящее в код, наз. кодовым словом. Число символов в кодовом слове наз. длиной слова. Кодовые слова могут иметь одинаковую или разл. длину. В соответствии с этим код наз. равномерным или неравномерным.
Цели К. и.: представление входной информации в ЭВМ, согласование источников информации с каналом передачи, обнаружение и исправление ошибок при передаче и обработке данных, сокрытие смысла сообщения (криптография) и т. д. Информационные свойства объекта, как правило, таковы, что код может быть представлен наиболее экономным образом. Эту задачу решает кодер источника, удаляя из сообщений избыточность. Дальнейшие этапы прохождения данных - передача по каналу передачи и (или) хранение в запоминающих устройствах - требуют обнаружения и(или) исправления ошибок, возникающих в них вследствие помех. Эти цели достигаются путём корректирующего кодирования, осуществляемого к о-дером канала. Наконец, защита информации от искажений при обработке в ЭВМ осуществляется применением арифметич. кодов.
Кодирование значений. Натуральное число N представлено в позиционной весомозначной системе счисления, если имеет место соотношение

где
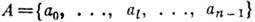 - цифровой алфавит с п цифрами,
- цифровой алфавит с п цифрами, 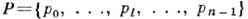 " - веса разрядов,
" - веса разрядов, 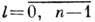 - номера разрядов. Термин "позиционная" означает, что в кодовом представлении (пли просто коде) числа, выражаемом условным равенством
- номера разрядов. Термин "позиционная" означает, что в кодовом представлении (пли просто коде) числа, выражаемом условным равенством
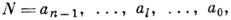
количественный эквивалент, сопоставляемый цифре а l, зависит и от её расположения в коде. Термин "весомозначная" означает, что каждый разряд имеет вес pl . Вес младшего разряда р 0 в цифровой измерительной технике отождествляется с разрешающей способностью аналого-цифрового преобразования. Выбор алфавита А и системы весов Р задаёт классификацию позиционных систем счисления (кодирование значений). В естественных системах

и, если n - основание системы счисления - натуральное число, любое число X может быть представлено как
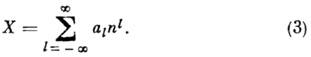
Выбор алфавита смещённым: А= (0, 1, . . ., п-1), А=(-п-1, . . ., 1, 0), или симметричным: А = (-п-1, . . ., -1, 0, 1, . . ., п-1) позволяет представлять соответственно положительные, отрицательные или любые числа. Симметричная система должна обладать нечётным основанием.
В ЭВМ почти исключительно используется позиционная двоичная смещённая система (n=2) с цифрами (0, 1) и естественным соотношением весов, представляющих ряд чисел
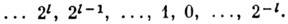
Возможно применение и иного набора цифр, напр. (-1, 1), дающего нек-рые специфические преимущества.
Развиваются двоичные системы, веса разрядов к-рых находятся не в естественном (2), а в более сложном соотношении, образуя, напр., ряд Фибоначчи (или "золотую пропорцию") [1]. Число N в коде Фибоначчи представляется соотношением
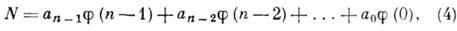
где
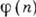 - числа Фибоначчи, связанные соотношением
- числа Фибоначчи, связанные соотношением
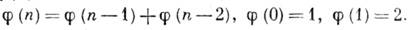
Разложение (4) числа N неоднозначно. Для любого N существует код, в к-ром не встречается двух следующих подряд нулей, а также код, в к-ром не соседствуют единицы. Эти, а также др. структурные особенности кодов Фибоначчи и "золотых" кодов делают их удобными для построения самокорректирующихся преобразователей, запоминающих и вычислит. устройств, сервоприводов с цифровым управлением и т. п.
Троичные системы счисления наиб. экономичны в том смысле, что именно в троичном коде определ. кол-вом знаков может быть выражено наибольшее разнообразие чисел. Есть основание полагать, что в будущем именно в силу указанного свойства троичная симметричная система кодирования с цифрами (-1, 0, 1) займёт в вычислит. технике доминирующее место. Проблемой остаётся создание элементов, реализующих ф-ции базиса в троичной логике: троичный инвертор и троичные НЕ-И или троичные НЕ-ИЛИ (см. Логические схемы),
Непозиционные коды применяют в специализированных измерит. и вычислит. устройствах [2]. Простейший из непозиционных - унитарный код можно получить, положив в (2) n=1 и р 0=1. В нём число N представляется как N=n+l - последовательно суммируемые единицы. Так работают, напр., счётчики импульсов.
Среди систем непозиционного кодирования выделяется система счисления в остаточных классах (СОК). Число N в СОК представляется в виде упорядоченного набора остатков (вычетов) по взаимно простым основаниям p1, . . ., р п;
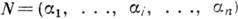 , где
, где 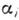 - наименьший вычет N по модулю р. Система оснований р 1, р 2, . . ., р п определяет диапазон представления чисел P=р 1, р 2, . . ., р п. В СОК арифметич. операции производятся независимо по каждому основанию и это позволяет существенно увеличить скорость их выполнения. В СОК удобен контроль операций, т. к. ошибки локализованы в пределах оснований. Специфичным для вычислит. устройств, работающих в СОК, является применение табличной арифметики: значения ф-ции, подлежащей вычислению, заранее заносятся в таблицу, а затем извлекаются при поступлении значений операндов.
- наименьший вычет N по модулю р. Система оснований р 1, р 2, . . ., р п определяет диапазон представления чисел P=р 1, р 2, . . ., р п. В СОК арифметич. операции производятся независимо по каждому основанию и это позволяет существенно увеличить скорость их выполнения. В СОК удобен контроль операций, т. к. ошибки локализованы в пределах оснований. Специфичным для вычислит. устройств, работающих в СОК, является применение табличной арифметики: значения ф-ции, подлежащей вычислению, заранее заносятся в таблицу, а затем извлекаются при поступлении значений операндов.
Эффективное кодирование источника информации [3] имеет целью согласование информационных свойств источника информации (ИИ) п канала передачи. Предполагается, что ИИ выдаёт на выходе сообщение, состоящее из букв m -буквенного алфавита
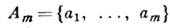
причём появление букв статистически независимо и подчинено распределению
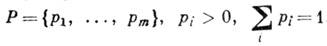
Источник характеризуется энтропией на символ
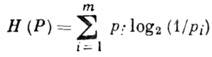
Энтропия
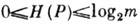 имеет смысл меры неопределённости относительно появления на выходе ИИ очередного символа. Равенство Н(Р)=0 достигается при вырожденном распределении Р, т. к. сообщение
имеет смысл меры неопределённости относительно появления на выходе ИИ очередного символа. Равенство Н(Р)=0 достигается при вырожденном распределении Р, т. к. сообщение
при этом детерминированно; равенство
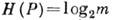 достигается при равновероятном появлении
достигается при равновероятном появлении 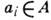 - ситуация наибольшей неопределённости. При m=2 и равномерном появлении букв а 1 и а 2 энтропия максимальна и Н(Р) = 1. Эта величина - неопределённость при равновероятном выборе из двух альтернатив используется как единица кол-ва энтропии - 1 бит.
- ситуация наибольшей неопределённости. При m=2 и равномерном появлении букв а 1 и а 2 энтропия максимальна и Н(Р) = 1. Эта величина - неопределённость при равновероятном выборе из двух альтернатив используется как единица кол-ва энтропии - 1 бит.
Пусть, далее, канал работает в г-буквенном алфавите и
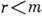 . Кодирование при этом будет заключаться в сопоставлении каждому символу
. Кодирование при этом будет заключаться в сопоставлении каждому символу 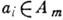 слова b( а i) в алфавите В r .
слова b( а i) в алфавите В r .
Каждый способ кодирования характеризуется ср. числом L(Р )букв выходного алфавита, приходящихся на одну букву входного алфавита А т. Для алфавитного кодирования
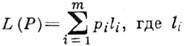 - длина слова
- длина слова 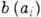 в алфавите В r. Если кодирование взаимно однозначно, то
в алфавите В r. Если кодирование взаимно однозначно, то
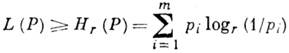
Величина I(P) = L(P)- Н r (Р )наз. избыточностью кодирования при распределении Р. Задача состоит в отыскании в заданном классе взаимно однозначных кодирований кодирования, обладающего мин. величиной I(P). Существование минимума и его значение устанавливаются теоремой Шеннона для канала без шума, гласящей, что для источника с конечным алфавитом А т с энтропией Н(Р )можно так приписать кодовые слова буквам источника, что ср. длина кодового слова L (Р )будет удовлетворять условиям
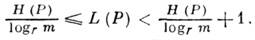
Оптимальным считается такой код, что никакой другой не обеспечит меньшего значения L(Р).
Конструктивная процедура отыскания оптим. кода для кодирования данного множества сообщений предложена в 1952 Д. Хафменом (D. R. Huffman). Идея заключается в том, что буквы алфавита А т упорядочиваются по вероятности и более вероятным приписываются более короткие кодовые слова. Код Хафмена обладает след. свойствами: слово, соответствующее наименее вероятному сообщению, имеет наибольшую длину; два наименее вероятных сообщения кодируются словами одинаковой длины, одно из к-рых оканчивается нулём, а другое - единицей (r=2).
Оптимальное равномерное кодирование. Пусть источник с двухбуквенным алфавитом
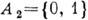 и
и 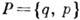 генерирует слова длиной l. Относительно всего множества из 2l слов (словаря источника) существует утверждение, что при
генерирует слова длиной l. Относительно всего множества из 2l слов (словаря источника) существует утверждение, что при 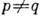 и достаточно больших l словарь источника распадается на два подмножества: группу из
и достаточно больших l словарь источника распадается на два подмножества: группу из 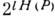 равновероятных слов (рабочий словарь источника) и группу слов с суммарной вероятностью, близкой к нулю ("нетипичные" последовательности). Здесь Н(Р) - энтропия на символ источника. Доля слов рабочего словаря весьма мала и с увеличением l стремится к нулю. Идея равномерного, или блокового, кодирования заключается в том, что кодер, получая на входе слова источника, сопоставляет кодовые слова лишь словам из рабочего словаря, кодируя все остальные одним словом, имеющим смысл ошибки. Вероятность ошибки может быть произвольно уменьшена увеличением длины слова источника. При этом объём кодируемых слов
равновероятных слов (рабочий словарь источника) и группу слов с суммарной вероятностью, близкой к нулю ("нетипичные" последовательности). Здесь Н(Р) - энтропия на символ источника. Доля слов рабочего словаря весьма мала и с увеличением l стремится к нулю. Идея равномерного, или блокового, кодирования заключается в том, что кодер, получая на входе слова источника, сопоставляет кодовые слова лишь словам из рабочего словаря, кодируя все остальные одним словом, имеющим смысл ошибки. Вероятность ошибки может быть произвольно уменьшена увеличением длины слова источника. При этом объём кодируемых слов 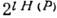 требует
требует 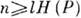 символов кодового слова. Поскольку слова рабочего словаря практически равновероятны, равновероятны будут и кодовые слова, а энтропия на символ кодового слова будет близка к 1 биту. Кодер, т. о., выдаёт слова длиной
символов кодового слова. Поскольку слова рабочего словаря практически равновероятны, равновероятны будут и кодовые слова, а энтропия на символ кодового слова будет близка к 1 биту. Кодер, т. о., выдаёт слова длиной  , экономя за счёт того, что "догружает" каждый символ до максимально возможной информационной нагрузки в 1 бит.
, экономя за счёт того, что "догружает" каждый символ до максимально возможной информационной нагрузки в 1 бит.
Кодирование источника приобретает новое значение в связи с необходимостью "сжатия" информационных массивов данных в базах и банках данных. Массивы организационной, экономич., измерит. информации имеют столь большую избыточность, что допускают сжатие, доходящее до 80-85%. Развитые системы управления базами данных (СУБД) имеют спец. программы (утилиты) анализа, сжатия и восстановления текста, работающие на принципах, изложенных выше.
Корректирующее кодирование информации. Его целью является обнаружение и (или) исправление ошибок в кодовых словах, возникших при передаче информации по каналу с шумом. Коррекция искажений возможна за счёт введения избыточности в систему передачи. При этом из всего множества слов кодера канала N0 лишь N будет соответствовать передаваемым сообщениям (разрешённые слова). Теоретически при этом доля обнаруженных ошибок не превыси 1-N/N0.
Предполагается, что информационное слово U= (u1, . . ., un), где uj=0, 1, поступает на вход кодера канала (в дальнейшем - кодера), ставящего ему в соответствие кодовое слово X (х 1 , . .., xl ),
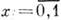 ,
,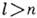 Кодер, т. о., добавляет по определ. правилу к слову U группу из k=l-n избыточных (корректирующих) разрядов. Кодовое слово X поступает в канал с шумом, где помеха искажает нек-рые из символов х i . Принятое на выходе канала слово Y= ( у 1, . . ., у 2) поступает на декодер, восстанавливающий (с пек-рым приближением) слово X. С кодовыми словами оперируют как с векторами в линейном векторном пространстве с метрикой Хэмминга, задающей расстояние между векторами
Кодер, т. о., добавляет по определ. правилу к слову U группу из k=l-n избыточных (корректирующих) разрядов. Кодовое слово X поступает в канал с шумом, где помеха искажает нек-рые из символов х i . Принятое на выходе канала слово Y= ( у 1, . . ., у 2) поступает на декодер, восстанавливающий (с пек-рым приближением) слово X. С кодовыми словами оперируют как с векторами в линейном векторном пространстве с метрикой Хэмминга, задающей расстояние между векторами 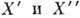
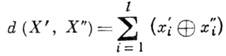
Теорема Шеннона для каналов с шумом, утверждающая, что при помощи подходящих кодов можно передавать информацию так, чтобы вероятность ошибки после декодирования была произвольно малой при условии, что скорость передачи не превосходит пропускной способности канала связи, неконструктивна: она не указывает способа построения кода. При конструировании кода решающее значение имеет выбор модели возникновения ошибок в передаваемом слове.
Наиб. распространена модель симметричного канала с равновероятными ошибками разл. типов - перехода, напр., символа 0 в 1 и 1 в 0.
Специфична модель канала "со стиранием". Выходной алфавит такого канала содержит спец. символ стирания, в к-рый и переходят символы входного алфавита при возникновении ошибки подобного типа.
Выдвигаются разл. предположения относительно распределения ошибок в передаваемой последовательности символов (кодовом слове). Возможна модель независимых ошибок (канала без памяти), модель сгруппированных ошибок (пачек ошибок), ошибок, расположенных на определ. расстоянии друг от друга, и т. д. Распространены предположения о предельной кратности ошибок в кодовых словах [3].
В рамках последнего предположения корректирующая способность кода оценивается числом ошибок, обнаруживаемых и (или) исправляемых с его помощью в кодовых словах. Предполагается, что в канале с X посимвольно суммируется (по mod 2) шумовой вектор Z, образуя слово
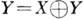 . Кратность возникающей в результате ошибки совпадает с числом единиц (весом Хэмминга) в Z. В векторе из l элементов не более чем r единиц могут быть размещены способами.
. Кратность возникающей в результате ошибки совпадает с числом единиц (весом Хэмминга) в Z. В векторе из l элементов не более чем r единиц могут быть размещены способами.
Это - то разнообразие ошибок, к-рое
 может возникнуть при передаче.
может возникнуть при передаче.
Основной характеристикой кода, определяющей его корректирующую способность по отношению к независимым ошибкам, является кодовое расстояние. Кодовое расстояние является наименьшим хэмминговым расстоянием между всевозможными словами
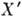 = (
= (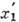 , . . .,
, . . ., 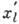 ) и
) и 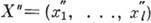 кода. Для того чтобы код обнаруживал все комбинации из s ошибок и исправлял все комбинации из t ошибок, необходимо и достаточно, чтобы кодовое расстояние было равно s+t+1.
кода. Для того чтобы код обнаруживал все комбинации из s ошибок и исправлял все комбинации из t ошибок, необходимо и достаточно, чтобы кодовое расстояние было равно s+t+1.
Широкий класс кодов для симметричного канала составляют линейные (групповые) коды [3], напр, коды Хэмминга, широко применяющиеся для защиты информации в основной памяти ЭВМ. Код Хэмминга обладает кодовым расстоянием d=3, исправляет однократные ошибки и обнаруживает двукратные. Он имеет проверочные разряды, расположенные в позициях с номерами 2°, 2, 22, . . . Линейный код задаётся парой матриц: порождающей
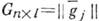 ,
, 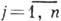 , и проверочной
, и проверочной 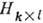 . Строки
. Строки 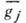 порождающей матрицы - линейно независимые векторы, образующие базис пространства, содержащего 2n элементов - кодовых слов. Каждая из строк проверочной матрицы ортогональна строкам
порождающей матрицы - линейно независимые векторы, образующие базис пространства, содержащего 2n элементов - кодовых слов. Каждая из строк проверочной матрицы ортогональна строкам 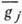 ,
, 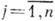 , и
, и 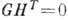
Кодер линейного кода образует кодовые слова по правилу XT=UTG. Модель искажений предполагает, что в канале с X посимвольно суммируется шумовой вектор Z, образуя слово Y=X+Z.
Идея декодирования заключается в образовании произведения ST=YT Н T, называемого синдромом. Равенство S = 0 означает, что Z=0, либо ошибка относится к необнаруживаемым. Синдром имеет 2k -1 ненулевых реализаций, каждая из к-рых может быть использована для указания на произошедшую ошибку.
Циклич. коды входят как подкласс в групповые коды. В них вместе со словом X входят и все его цик-лич. перестановки. Кодовые слова образуются как произведение двух полиномов: U (Е )степени п-1, коэф. к-рого составляют информационное слово U, и порождающего g (Е )степени l-п, неприводимого и делящего без остатка двучлен (1+El). Декодирование заключается в делении принятого слова (полинома) на g(E). Наличие ненулевого остатка укажет на присутствие ошибки. Циклич. коды, как правило, несистематические.
Спец. циклич. коды предназначены для обнаружения и исправления пачек ошибок, напр, коды Файра, определяемые порождающими полиномами вида g(E) = =p(E)(Ec+1), где р(Е) - неприводимый полином, а величина с определяется длиной исправляемых и обнаруживаемых пачек ошибок.
Пачки ошибок характерны для запоминающих устройств с магн. носителями, в частности для накопителей на магн. дисках (НМД) совр. ЭВМ (см. Памяти устройства). Для защиты данных в НМД поэтому широко используется К. и. циклич. кодами, осуществляемое аппаратными средствами.
Арифметические коды предназначены для обнаружения ошибок, возникших при выполнении арифметич. операций на ЭВМ. В теории арифметич. кодирования вводятся понятия веса, расстояния и ошибки, отличные от хэмминговых. Арифметич. вес числа определяется как мин. число слагаемых в представлении числа в виде
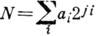 ,
, 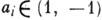 . Ошибки, в результате к-рых величина числа изменяется на
. Ошибки, в результате к-рых величина числа изменяется на 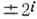 , г'=0, 1, 2, . . ., наз. арифметическими. Арифметич. расстояние между N1 и N2 - арифметич. вес разности
, г'=0, 1, 2, . . ., наз. арифметическими. Арифметич. расстояние между N1 и N2 - арифметич. вес разности 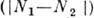 , равно кратности ошибки, переводящей число N1 в N2, и определяет корректирующую способность арифметич. кода подобно расстоянию Хэмминга.
, равно кратности ошибки, переводящей число N1 в N2, и определяет корректирующую способность арифметич. кода подобно расстоянию Хэмминга.
В распространённых AN- кодахкодирование числа N - операнда - осуществляется умножением его на специально подобранный множитель А. Так, 3А-код, имея кодовое расстояние 2, обнаруживает одиночные ошибки путём деления суммы на 3. Ошибки обнаруживаются при ненулевом остатке: величина арифметич. ошибки 2i не делится на 3 нацело. Кроме одиночных при A=3 обнаруживается и часть двойных ошибок - те, при к-рых правильный и ошибочный результат имеет несовпадающие остатки от деления на 3.
Криптография осуществляется путём подстановки, когда каждой букве шифруемого сообщения ставится в соответствие определ. символ (напр., др. буква), либо путём перестановки, когда буквы внутри искусственных блоков текста меняются местами, либо комбинацией этих методов. Шенноном показано, что возможны криптограммы, не поддающиеся расшифровке за приемлемое время [5].
Лит.:1) Стахов А. П., Введение в алгоритмическую теорию измерения, М., 1977; его же, Коды золотой пропорции, М., 1984; 2) Акушский И., Юдицкий Д., Машинная арифметика в остаточных классах, М., 1968; 3) Г а л-л а г е р Р., Теория информации и надежная связь, пер. с англ., М., 1974; 4) Д а д а е в Ю. Г., Теория арифметических кодов, М., 1981; 5) Аршинов М. Н., Садовский Л. Е., Коды и математика, М., 1983. Л. Н. Ефимов.
Физическая энциклопедия. В 5-ти томах. — М.: Советская энциклопедия. Главный редактор А. М. Прохоров. 1988.
.