- Универсальный код (сжатие данных)
-
Универсальный код для целых чисел в сжатии данных — префиксный код, который преобразует положительные целые числа в двоичные слова, с дополнительным свойством: при любом истинном распределение вероятностей на целых числах, пока распространение — монотонно (то есть
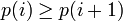 для любого i), ожидаемые длины двоичных слов находятся в пределах постоянного фактора ожидаемых длин, которые оптимальный код для этого распределения вероятностей назначил бы.
для любого i), ожидаемые длины двоичных слов находятся в пределах постоянного фактора ожидаемых длин, которые оптимальный код для этого распределения вероятностей назначил бы.Универсальный код асимптотически оптимален, если коэффициент между фактическими и оптимальными ожидаемыми длинами связывает функция информационной энтропии кода, которая приближается к 1, так как энтропия приближается к бесконечности.
Большинство префиксных кодов для целых чисел назначают более длинные ключевые слова большим целым числам. Такой код может использоваться, чтобы эффективно закодировать сообщение, тянущееся из набора возможных сообщений, просто упорядочивая набор сообщений по уменьшению вероятности а затем пересылая индекс предназначаемого сообщения. Универсальные коды в общем не используются для точно известных распределений вероятностей.
Универсальные коды включают в себя:
- Унарное кодирование
- Гамма-код Элиаса
- Дельта-код Элиаса
- Омега-код Элиаса
- Дельта-код
- Кодирование Фибоначчи
- Кодирование Голомба
- кодирование Райса
Взаимоcвязь и практическое использование
Использование кода Хаффмана и арифметического кодирования (когда они могут использоваться вместе) дают лучший результат, чем любой другой универсальный код.
Однако, универсальные коды полезны, когда код Хаффмана не может использоваться — например, когда невозможно определить точную вероятность каждого сообщения, но известно ранжирование их вероятностей.
Универсальные коды также полезны, когда код Хаффмана отрабатывает не совсем корректно. Например, когда отправитель знает вероятности сообщений, а получатель нет, код Хаффмана требует передачи вероятностей к получателю. Использование универсального кода избавляет от таких неудобств.
Каждый универсальный код дает собственное «подразумеваемое распределение» вероятностей p(i) =2-l(i), где l(i) — длина i-го ключевого слова и p(i) — вероятность символа передачи. Если фактические вероятности сообщения — q(i) и расхождение Кульбака-Лейблера DKL(q||p) минимизирует код с l(i), затем оптимальный код Хаффмана для этого множества сообщений будет эквивалентен к этому коду. С тех пор, как универсальные коды стали работать быстрее, чтобы кодировать и декодировать, чем код Хаффмана, универсальный код был бы предпочтителен в случаях, где DKL(q||p) достаточно маленький.
Для любого геометрического распространения кодирование Голомба оптимально. С универсальными кодами, подразумеваемое распространение — приблизительно энергетический закон как например 1 / n2. Для кода Фибоначчи, подразумеваемое распространение составляет приблизительно 1 / nq.
Ссылки
Wikimedia Foundation. 2010.